HBase触ってみた
皆さんこんばんは。花粉が舞いに舞っている昨今、いかがお過ごしでしょうか。 春といえば、OSSのDBが恋しくなります。ということで、HBaseを今日一日触っていたので、その記録を書こうかと思います。
というのも、オライリーのデータ指向アプリケーションデザインの第6章「パーティション」を読んでいて、実際にプロダクトを触りたくなってきたからです。
データを分散して分けた1つ1つをパーティションと呼び、それをどのように分けるか?はたまたどのようにリバランシングするか?
などが載っていました。概念は理解しましたが、実際に実装だとどういう感じなのか理解したかった次第です。
HBaseとは?

- ApacheのOSSのプロダクトのうちの1つ。
- HDFS(Hadoop Distributed File System)上に構築するデータベース。
- HDFSは、Hadoopに使われる分散ファイルシステム。いい感じに分散してファイルを保存する。
- NoSQLの中のワイドカラム型に属する。
- キーバリュー型の拡張。1つのキーに対して複数の列を持つことができる。
- Regionという単位でデータを分散して持つ。そしてそのRegionをスレーブノードに割り当てる。
- スレーブノードは他のPC1台に当たる。つまり、PC1台を追加する(スレーブノードを追加する)と、Regionが新たに割り当てられてスケールアップする。
HBaseの概要とアーキテクチャ | Think IT(シンクイット)
ここを読めばかなり詳しくわかります。
いわゆるMPP(Massively Parallel Processing)はRDBMSが並列処理を可能にしたものだけど、それとはまた別流派の分散DBといった感じでしょうか。
とにかく、パーティションを実現できるOSSなので、HBaseを今回は触ってみたいと思います。
HBaseのインストール
環境
Windows10
Docker version 20.10.5
docker-compose version 1.29.0
上記のWindows端末で実行していきます。
DockerでHBaseのコンテナ作成
① 資材をcloneしてくる
GitHub - big-data-europe/docker-hbase
上記のリポジトリをcloneしてきましょう。
Windowsでのgitのインストールはここなど詳しいです。
【Windows】Gitの環境構築をしよう! | プログラミングの入門なら基礎から学べるProgate[プロゲート]
ちなみに、以下の2つがdocker-composeファイルです。
今回は、分散処理させてみたかったので「distributed-local」の方を使います。
・docker-compose-distributed-local.yml
・docker-compose-standalone.yml
② ビルド実行
cloneした場所にPowerShellで移動して、以下を実行します。
docker-compose -f docker-compose-distributed-local.yml up -d
これでymlファイルに記載されているコンテナが複数ビルドされ、さらに立ち上がるはずです。
私はこれとは別にDocker Desktopも入れていますが、それ上ではこのように見えています。

③ WEB UIで確認
http://localhost:16010
にアクセスしてみましょう。
上手くHBaseが立ち上がっていれば、以下のような画面になります。
(テーブルやRegion数はいじった後なので、立ち上げ直後とは異なると思います)

参考
以下のページを参考にしました。
docker composeを使って「hbase」を構築するまでの手順 | mebee
HBaseのインストールと実行方法(スタンドアロンモード) - TASK NOTES
HBaseでのテーブル作成
テーブル作成、データ挿入
① コンテナログイン
マスターノードにログインします。「hbase-master」がマスターノードのクラスター名です。
docker exec -it hbase-master /bin/bash
② hbase-shell起動
(ここからはマスターノード上でコマンド実行します)
ログイン出来たら、以下のコマンドで対話型のコマンドラインツールを起動します。
hbase shell
次からは、このツール上でhbaseに色々なコマンドを打っていきます。
③ テーブル作成
create文でテーブルを作成します。
create 'テーブル名', 'ColumnFamily名' です。
create 'test_table', 'cf'
④ テーブル確認
WEB UI上で確認します。
以下のように、新しいテーブルができていれば成功です。
このテーブルは、Online Regionsがまだ1なので、分散されていない状態ですね。

⑤ データ挿入
put文でデータを挿入します。
put 'キー名', 'ColumnFamily名:Column名', 'バリュー' です。
put 'test_table', 'row1', 'cf:col1', 'value1'
このあたりの関係性は、以下のページが分かりやすいです。
HBaseのアーキテクチャを理解しよう (1/3):CodeZine(コードジン)
⑥ データ確認
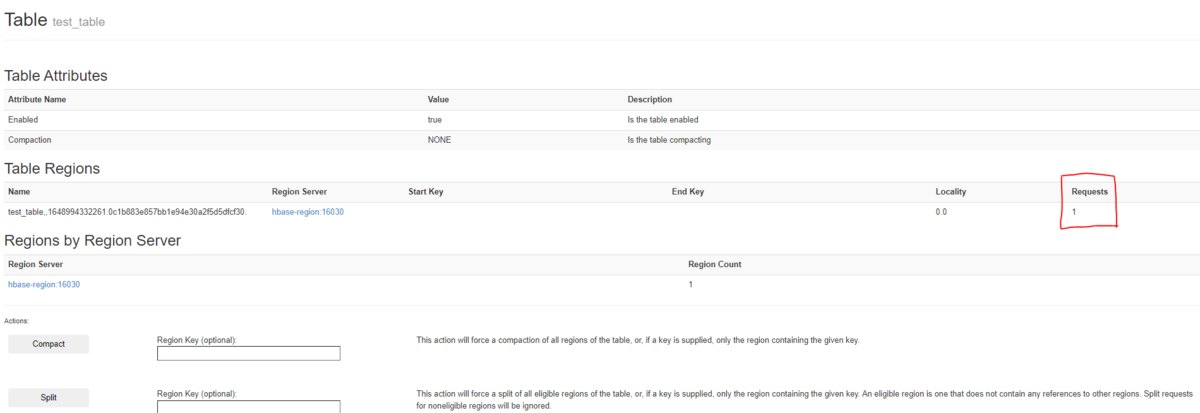
WEB UI上で、Tableをクリックすると以下の画面に遷移します。
赤枠で囲っている、Requestsが1になっていればデータが挿入されています。
(「scan 'table名'」をhbase shellで打っても、データの内容は確認可能です)
HBaseでのパーティション確認
さて、ここからが本題。パーティションです。
事前パーティション
① 事前パーティションを定義してテーブル作成
以下のコマンドで、新しいテーブルを作成します。
今度は、キーの範囲でパーティションを切るように指定しています。
create 'test_table2', 'cf', SPLITS => ['1000','2000','3000','4000']
② 確認
WEB UIで確認します。
~1000 / 1000~2000 / 2000~3000 / 3000~4000 / 4000~
の5つのパーティションが作成されていることが分かります。

③ データを挿入
1000~2000のパーティションにデータを挿入してみます。
今回は、キーを'1234'にしてみましょう。
put 'test_table2', '1234', 'cf:col1', 'value1'
④ 確認
WEB UIで見ると、ちゃんと想定のパーティションのRequestsが1となっていますね。

パーティションの強制分割
ここでは、今5つに分けられているパーティションのうちの1つを強制的に分割してみます。
以下のページを参考にしています。(ちなみに、強制マージはできないそうです)
Apache HBase Region Splitting and Merging - Cloudera Blog
① 分割
ここでは、split文を用います。
split '8efadd362101393ea6e29e7cc7ee3fd0'
split 'encoded region name'
とすることで、指定のパーティションが分割されます。
'encoded region name'は、テーブル名とパーティションの開始の値(1000など)とtimestampのハッシュを取ってエンコードされたものだそうです。
参考:HBase hbckについて その1 - Qiita
'encoded region name'は、WEB UIだとここに表示されています。

② 確認
WEB UIで確認してみますが…
変化がないです。なぜかパーティションが分割されていませんね。
データ量が少なすぎた?少し大きいデータをいくつか挿入してみましょう。
③ データ挿入
以下のput文を、キーの値が1100, 1300, 1600, 1900の4種類ごとに10回打ちました。
100万文字は半角数字だったので、1回につき約1MBですね。
そのため、全部で40MBのデータを挿入した計算になります。
put 'test_table2', '1100', 'cf:col1', '[100万文字]'
さて、これでsplitを再度打ってみましょう。
(一応、split打つ前はこんな感じ。Requestsが44に増えてます)

④ splitと確認
前と同じsplit文を打ちます。
split '8efadd362101393ea6e29e7cc7ee3fd0'
結果はこちら。

見事に2つに分かれている…が、分割しているキーの範囲が何かおかしい?
1100, 1300, 1600, 1900に分けたので、1500くらいで分割されてくれると思いましたが。。
これは原因不明です。わかる方いたら教えてください。
自動パーティション分割
こちらは、HBaseのver0.94以降では、
Min (R2 * “hbase.hregion.memstore.flush.size”, “hbase.hregion.max.filesize”)
この式を超えると自動で分割されるそうです。
この2つは設定値で変更可能です。
・"hbase.hregion.memstore.flush.size”
・“hbase.hregion.max.filesize”
また、Rは同じテーブル内の現在のリージョンの数。
例えば、まだ1個しかリージョンが割当てられていない状態で、"hbase.hregion.memstore.flush.size”が128MBだとすると、その時は128MBを超えたら分割されます。
次は、2個割り当てられているのでRは2です。そのため、22 * 128MB=512MB を超えたら分割されます。
本当はこれを試してみたかったですが、このサイズのデータを挿入するのがかなりしんどいため見送りました。
どなたかやってみてください。
まとめ
- HbaseはOSSの分散データベース。
- docker-composeを使って簡単に構築可能。
- テーブル作成の際にパーティションを指定できる。
- splitコマンドで強制的に分割できる。
- なぜかきれいなパーティション範囲で分割できず。
- 自動分割も可能。設定値を変更すれば閾値も変えられる。
OSS知識欲が出てきたため、Sparkなども触ってみたいですね。
それでは。