約2週間ほど前になりますが、取り組んでいたColeridgeコンペが終了しました。
結果は残念なものでした(Public:163/1610 → Private:510/1610)が、記録として振り返っておこうと思います。
コンペ概要
様々な分野の論文のテキストデータが与えられて、その中からデータセット名を特定します。
トレーニングデータとして1つの論文のテキストデータが1つのjsonとして与えられていて、そのjson1つに対して複数の正解ラベル(データセット名)が与えられます。
例えば、実際のトレーニングデータの一部で以下のテキストがあります。
Any college degree attainment The study author collected information on college degree attainment from the fourth follow-up of the National Education Longitudinal Study collected in 2000.
この太字で示しているNational Education Longitudinal Studyが正解ラベルのデータセット名です。
テストデータはこのテキストだけが与えられていて、その中からデータセット名を当てる必要があります。
ただ、今回のコンペはCodeコンペなので、テストデータはほとんど隠されています(手元に与えられるテストデータは4つのjsonだけ。実際はPublicは約1000、Privateは約8000ほどの論文が与えられます)。
やったこと
今回はメモ程度の日記をつけながらやったのでいろいろと記録してあります。
まず、今回のコンペで費やした時間は78時間でした。
(それでこの体たらくかよ、というツッコミは置いておいて…)
前半戦-自力でモデル構築
前半は、ほとんどNLPのコードをまず動かすことに使ってました。
ちょうどこの本を持っていたので、この本の実装を今回のコンペに当てはめて動かしていました。
")
今回のコンペの問題は、固有表現抽出が使える!と考えたので、Chapter10を読んで実装しました。
固有表現抽出とは、こういうやつ。(wikiより)
固有表現抽出(こゆうひょうげんちゅうしゅつ、英: named entity recognition、named entity identification、named entity chunking、named entity extraction)とは、計算機を用いた自然言語処理技術の一つであり、情報抽出の一分野である。文中から固有表現 (Named Entity) を抽出し、それを固有名詞(人名、組織名、地名など)や日付、時間表現、数量、金額、パーセンテージなどのあらかじめ定義された固有表現分類へと分類する。
テキストデータの中のデータセット名を固有表現としてラベリングしておけば、このタスクで解けるじゃないか!
ということです。
Discussionみても、ところどころ使っている人はいたので、それなりに筋はいいかなと進めていました。
LSTMモデルを使う方法と、その次にBERTを使う方法を試して、初SUBできた時点で32時間経過でした。
内容は本がわかりやすかったですが、サイトではここら辺がわかりやすい。
hironsan.hatenablog.com
テキストを自分でラベリング(単語ごとに、「これは固有表現」「これは違う」のラベリング)しなくてはいけないのと、モデルに合わせて単語をベクトル化したりトークン化(英単語を数字へ)したりしなくてはいけないので、前処理が結構面倒でした。
ただ、前者はやってくれているKernelがあり、後者はtransformerのメソッドが存在する+本から丸パクリで何とか実装しました。
今後もここで書いたコードは使えそう。
後半戦-モデル、後処理の改善
後半は、この実装したモデルとテキストマッチングを合わせてsubをしていきました。
今回、機械学習で正解を当てるほかに、「世の中のデータセット名を頑張って集めてきて、それらとテキストマッチングさせる」というテキストマッチング手法が流行りました。
ただ、コンペ主催者から、「使ったサイトは公表するように」とあったため、additionalなデータセット名は公開されてました。
そのため、論文ごとにそのデータセット名とマッチングさせて、そのマッチングが0なら機械学習で推定するという方法がKernel内では流行ってました。
他にも、機械学習で出した答えとこのマッチングの結果のORを取るとか、ANDを取るとか、条件付きでANDを取る(類似度が低いもの限定)とかやってみましたが、
上記の方法が一番PublicScoreが高くなりました。
と色々書きましたが、結果的に一番PublicScoreが高かったのは公開Kernelを使ったものというオチでした。笑
自分で学習させたモデル+テキストマッチングは、どうやってもスコアかなわずとなりました…。
(fold=3でCrossValidationさせたりと色々してスコア自体は上がっていったのですが、どうやっても公開カーネルには届かず。)
最終的には、
・PublicScoreが一番高い公開Kernel
・テキストマッチングはしないで、自作のモデルで推論した結果だけのもの
以上の2つをSubとして提出しました。
2つ目は、Privateにテキストマッチングするものが少なかった時にShakeが起きるだろうと予測して、一応選びました。
公開Kernelのモデルだけを使った方がよいのでは?とも思いましたが、選べなかったときに後悔する度から自作のモデルを選びました。笑
結果、Privateではどちらもスコア振るわずとなりました。
大切だったこと
コンペ終了後、Discussionや個人ブログやtweetなどを読み、大切だと感じたのは、以下2つです。
① トレーニングデータには、未知の正解ラベル(データセット)が存在している。
② テストデータ(Public)にはトレーニングデータと同じ論文が含まれている。(≒テストデータ(Private)にはほぼ含まれていない)
①は分かりにくいので、図を描きました。
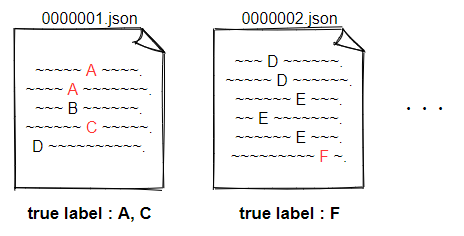
トレーニングデータには、jsonに対応して正解ラベルが付与されていますが、全ての正解ラベルが付与されているわけではないということです。
例えば図の0000001.jsonは、実際の正解ラベルはA,B,C,Dの4つですがトレーニングデータとしてはA,Cの2つしか付与されていない、ということが起きています。
これのせいで、トレーニングデータのラベルをそのまま使って学習させても、良いモデルができません。
どれだけ良いモデルを使っても、学習時に「正解ラベルはA,Cだぞ!」と学習させたら、BとDは推論できないですからね。
私が作ったモデルがダメだったのは、これを考慮せずに学習させていたからだと思われます。
他の方々を見ると、まずは正規表現などで未知の正解ラベル(データセット)を当てに行く手法が多かったです。
例えば、正解ラベルを見ていくとデータセット名はすべて1文字目が大文字であったり、データセット名の後にカッコで略称が入っていたりするものが多いです。
それらをルールベースで見つけていく、という機械学習は使わない方法です。
それで見つけたものをさらに学習データとしてモデルを構築するという人が多かったです。
②は、今回のfinalSubの選択基準に大きくかかわるところでした。
これはコンペのDataタブの説明欄に書いてあったことです。
A percentage of the public test set publications are drawn from the training set - not all datasets have been identified in train, so these unidentified datasets have been used as a portion of the public test labels.
このため、いくらPublicでスコアが高くてもそれは「トレーニングデータで出てきている正解ラベルを当てただけ」という可能性が出てきます。
この影響をなくして、Privateのスコアの高さを見るには、最終的な推論結果からトレーニングデータの正解ラベルを削除してsubmitすることが必要です。
こうすれば、純粋に未知のラベルをどれだけ当てているか?を判断でき、Privateと同じ状況となります。
実際、LateSubmitでいくつか試してみましたが、以下のような結果となりました。
public : private : public(delete train labels)
0.576 : 0.195 : 0.182
0.574 : 0.226 : 0.214
0.545 : 0.246 : 0.237
見事に、今回の正解ラベルを削除してsubmitしたスコアとprivateスコアの大小関係が一致しています。
逆に、ただsubmitしただけのスコア(一番左)はprivateとは逆転していますね。
これは、この方の書き込みからわかりました。
この方の出しているKernelも読みましたが、とてもすごい。
既知のラベルがpublicにも含まれているというところから、テストデータには1つのjsonファイルに平均10個の正解ラベルがあるということを導出されています。
トレーニングデータは平均1個ちょいなので、テストデータにはかなり未知のラベルが多いことになります。
よってsubの推定結果から既知ラベルを全て除いた上でpublic scoreが最も高いモデルを採用すればprivateに最適なsubが作れると分かっていた。
— OsciiArt◆SPNEXTcRxQ (@osciiart) June 23, 2021
MLMモデルについて
ちょっと話は飛んで、使用したモデルについてです。
私は固有表現抽出モデルを作りましたが、KernelではMLMモデルが流行っていました。
テキストのある部分をマスクして、そのマスク部分の単語を機械学習で導出するというモデルです。
まずはデータセット名っぽいところ(単語の1文字目が大文字か、inなどの前置詞のもの)をマスキングして、それがデータセット名かを予測させるモデルでした。
学習kernel
[Coleridge] BERT - Masked Dataset Modeling | Kaggle
推論kernel
[Coleridge] Predict with Masked Dataset Modeling | Kaggle
こちらのモデルはPrivateでもスコアが落ちることなく優秀で、自分の提出したカーネルのモデル部分をこれに置き換えるだけで、銅メダルスコアが出ました。
学習の中で、ただ正解ラベルをインプットにしているだけでなく、「データセット名っぽいところ」もインプットにしているため、これが
「① トレーニングデータには、未知の正解ラベル(データセット)が存在している。」の対策になっていたのではないかと思います。
ただ、いくつかわからない点もありました。
・学習時、正解ラベルを渡していないように見える。どうやって学習させている?
・推論した結果がネガティブデータ(データセット名ではないもの)であっても予測結果に加えているように見える。なぜ?
ここは正直よくわかりませんでしたが、上記の理由からスコアが落ちなかったのではないかなと思います。
今回のコンペの学び
・train、test(public), test(private)のデータはどのように分けられているかをもっと調べよう。
・データを見て、方針を立てよう。(正規表現で行けるんじゃないか?など)
・DeepLeraning系のコンペでは、モデルはkernelで出ているやつをまず使おう。自作はその次。
…当たり前のことをしっかりやる。次は勝つ。以上!
参考
以下の2つのブログは振り返るうえで非常に参考になりました。
やっている内容も私より全然高度で、かつブログとしても読みやすい。
kaggle、ナニモワカラナイのレベルにいるなと改めて実感しました。。
【Kaggle】 Goldを目指したけど、木っ端微塵に砕け散った話|しょーた|note
Kaggle Coleridge 52nd solution - 情報系院生のノート