ネットワークのお勉強~AWS VPCを添えて
皆さんこんばんは。寒い日が続くと思ったら、もう年の瀬ですね。
今年もいろいろと激動な日々でしたが、そんな変化の激しい現代社会を根底から支えるクラウドサービス、それがAWSですよね。
今回は、AWS SAAの勉強をしていて、VPCについて学んだ(それを通してネットワーク全体についても学んだ)ので、それをここに書いていこうと思います。
ただ、世の中に同じようなブログはゴマンとあるため、細かい説明はググるとして、一連の流れを後でも追えるように記事を書きたいと思います。
一連の流れとは何か?というと、
(1)インターネットを通って、プライベートサブネット内のEC2にアクセスする流れ
(2)プライベートサブネット内のEC2からインターネット上のどこかにアクセスする流れ
の2つです。
(1)インターネットを通って、プライベートサブネット内のEC2にアクセスする流れ
図と文字で説明します。こちらは比較的素直。
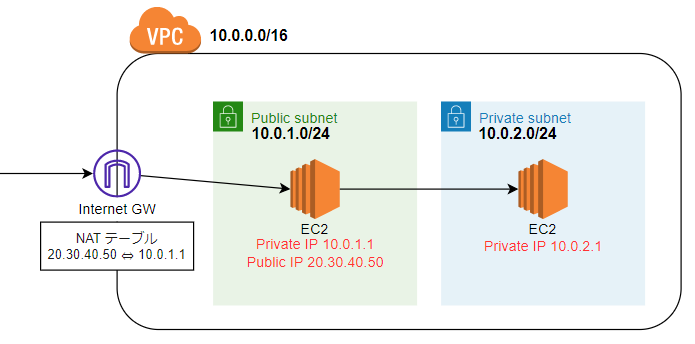
- Teratermなどで、PublicのEC2のIP20.30.40.50を指定する。
- Internet GWで、パブリックとプライベートのIPを変換する。つまり、20.30.40.50→10.0.1.1に変換する。
- パブリックのEC2到着!
- そこから、さらにIP10.0.2.1に対してssh通信する。
- 同じVPC内なので、そのままプライベートのEC2到着!
この流れの中で、私がちょっと気になった部分をピックアップ。
・インターネットGWはIPの変換をしている。
StaticNATを行います(静的なIPの変換)。NATテーブル(変換するIPのテーブル)には、通信前から変換ルールが定義されているため、インターネットから始まる通信/EC2から始まる通信、どちらにも対応可能です。
・ネットワーク疎通確認しようとしてもpingは通らない。
pingは、sshではなくICMPプロトコルでの通信であるため、デフォではセキュリティグループで許可されていません。
セキュリティグループとネットワークACLは、VPC内の通信制御の機能です。どちらもプロトコル、ポート、IPで通信の許可/拒否を定義できます。
セキュリティグループ:インスタンス単位で制御。ステートフル(来る通信が許可されていたら、返りも無条件で許可)
ネットワークACL:サブネット単位で制御。ステートレス(来る通信が許可されていても、返りも「許可」が定義されていないと通らない)
・InternetGWのNATテーブルは使用者は意識しない。
内部の仕組みでは、InternetGWのNATテーブルでプライベートとパブリックのIPを変換しているみたいですが、利用者はこんなテーブル気にしないでOKです。その代わり、EC2の設定画面で設定します。
ちなみに、EC2の設定画面で設定するとランダムなIPが割り振られますが、ElasticIPというサービスを使うと固定IPを払い出せて、それをEC2に紐づけることも可能です。
(2)プライベートサブネット内のEC2からインターネット上のどこかにアクセスする流れ
こちらも図と文字で説明します。こっちはちょっと複雑。(と言っても、AWS上での設定は楽)
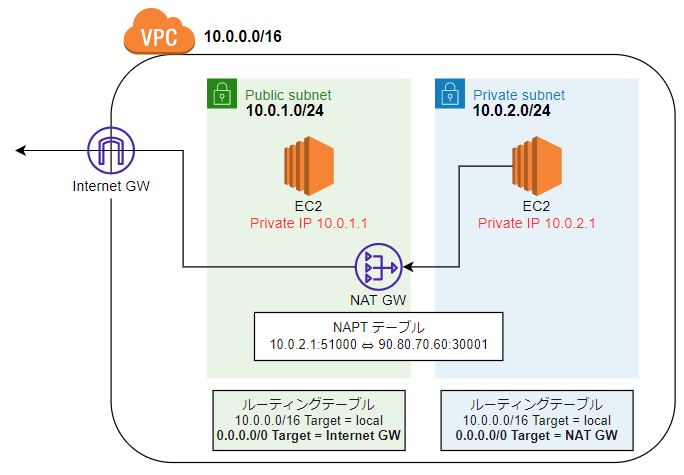
- プライベートのEC2から、インターネット上のどこかにアクセスするコマンド実行する。
- Private Subnetのルーティングテーブルをチェック。10.0.0.0/16以外のIPにアクセスする場合はNAT GWに行くようになっているため、NAT GWにアクセスする。
- NAT GWで送信元のプライベートとパブリックのIPをポートを含めて変換する。つまり、10.0.2.1:52000→90.80.70.60:30001に変換する。
- Public Subnetのルーティングテーブルをチェック。10.0.0.0/16以外のIPにアクセスする場合はInternet GWに行くようになっているため、Internet GWにアクセスする。
- Internet GWではNATはしないでインターネットへのルーティングのみ実施する。
- インターネット上の目的地に到着!(実際はレスポンスもある)
・NAT GWはポートを含めて変換している。
Dynamic NAPTを行います(動的なIP+ポートの変換)。通信が来たらそのタイミングでNAPTテーブルを定義するため、プライベートからインターネットに出たときのレスポンスは返ってきます(NAPTテーブルに変換するIP+ポートが記載されているため)。しかし、インターネットからの通信はされません(パブリックサブネットのルートテーブル内に、インターネットGWからNATゲートウェイにルーティングするルールは書いていないため)
また、ポートを含めていることによって、NATGWは1:多の変換を可能にしています。そのおかげで、プライベート内のEC2が複数あっても、NATGWは1つでOKです。
・NAT GWで変換するIPは事前にElasticIPで払い出してNAT GWに紐づけておく。
NAPTテーブルに記載された、パブリックIPですが、これは事前に払い出しておきます。こちらは、動的に作成するわけにはいかないため、ElasticIPで固定IPを払い出しておきます。
ちなみに、ElasticIPは固定IPを払いだして、何も紐づけていないと課金されます。EC2とか、今回のようにNAT GWに紐づけていれば無料です。
また、NAT GWの料金は結構お高いみたいです。実際に設計するときは、ここら辺のコストも気にする必要がありますね。
私が学習中に躓いたポイントを踏まえて、2つの流れを追ってみました。
ちなみに、このサイトをかなり参考にしました。
【図解/AWS】インターネットGWとNAT-GWの違い〜各メリット、パブリックサブネットとは〜 | SEの道標
なんとなく、ネットワークについて激浅な知識がついた気がします。
ちょっと知ると、こういう本読みたくなってきますよね。とりあえず年末用に買って、お守りとして持っておこうかと思いました。それではみなさん、よいお年を。
")
ベイズ法の統計的アプローチ
皆さんこんばんは。だいぶ冷え込んできましたね。今日、ユニクロでフリースを購入してきました。
さて、先週は2年ぶりの開催となる統計検定1級が開催されました。
午前中の試験官は、問題用紙を配り忘れるという大ポカをかましてきまして、ドタバタのスタートとなりました。
むしろそれすること以外仕事ないだろ…。ちゃんとしてくれ。
とまぁ、内容は来月の結果発表が来てからまとめようと思いますが、
統計数理:おそらく桜散る
応用:ワンチャンス。
といったところです。応用は部分点の波をとらえられていれば、ギリギリ桜に手が届くかな、という雰囲気。
興奮冷めやらぬままに解けなかったところを解いていたんですが、まぁわからない。
統計検定側も略解をすぐに出してくれたのですが、これが略解すぎる。ポケモンで言うと、ニビとシルフカンパニー本社と殿堂入りシーンくらいしか書いていない。
なので結局理解が1ミリも進まなかったので、ほかの方のブログなどで回答が出るまで解かないことにしました。
ただ、その途中でベイズ法について少し知ったので、ここに記します。
ベイズの定理とは何か?!と色々調べたところ、これが一番まとまってました。
θをパラメータの確率変数、xをデータの確率変数としたときに
と表せ、この時
こうなる。これはつまり、
事後分布(確率)∝ 尤度 × 事前分布(確率)
になりますよ、と。
xはデータの確率変数なんだから、それが事前確率になっているP(θ|x)は更新された後のパラメータに関する分布。
P(x|θ)はパラメータが与えられた時の確率変数の分布なので、全てのx1,x2,…xnに関しての分布を掛け合わせて求める尤度。
そしてP(θ)はそのまま事前分布。
これで事後分布を求めましょう!という話。
現代数理統計学の基礎のp.125には、例題として、
X~Bin(n, p)として、事前分布にBeta(α, β)を仮定する。その時の事後分布は~という流れで、それぞれを掛け合わせたものを変形してまたBeta分布の形を導出。
つまり、事後分布もBeta関数の形ですね、という問題を扱っていました。こういう風にやるのね。
と、ここまでわかったんですが、2021年の試験のベイズが解けない!!!早く世の中の頭いい人回答plz
ただ、多分そんなに難しいことしてないと思うんだよなぁ…。
ということで、他力本願でとりあえず待とうと思います。
統計が落ち着いた?ので次はAWSの資格を乱獲していくぞ!!!と思い立ちUdemy講座を購入。
またまとまって受けられたら記事にします。
一様分布を侮るなかれ
皆さんこんばんは。すっかり寒くなってきましたね。
11月といえば、勤労感謝の日、ポッキープリッツの日…そう、統計検定1級の受験日ですね。
今年の受験日は11/21(日)なので、あと1週間となってしまいました。
一応今年の夏から勉強してはいますが、やはり難しい。
ここまで、おそらく60時間くらいは勉強しているはず。ただ、それでももちろん全範囲は終わっていないし、かつ理解も結構甘い。
やはり、正規分布やベータ分布が絡むところの積分計算や、点推定の分野の不偏性、一致性の証明など、難しい!!!
半分あきらめモードで進めています。
ただ、その中でも、「これ覚えてないと無理ゲーだけど、知ってたら結構おいしいな」という問題がありました。
それは、一様分布。2017年から2019年までは皆勤賞です。しかも、分布自体が非常に簡単なので、単純な期待値とか聞いてきません。
特に詰まったのは2018年問5で出てきた、順序統計量についてでした。この過去問を使いながら、一様分布の順序統計量について解説していこうと思います。
2018年統計数理 問5
確率変数X1,X2,X3は互いに独立に区間(0,1)上の一様分布に従うとし、それらの順序統計量をX_(1)≦X_(2)≦X_(3)とする。Y1=X_(1), Y2=X_(2), Y3=X_(3)と置き、Z=Y3-Y1としたとき、以下の各問に答えよ。[1] Y1とY3のそれぞれの確率密度関数f1(y), f3(y)および期待値E[Y1], E[Y3]を求めよ。
[2] Y2の確率密度関数f2(y)を求めよ。また、確率P(Y2<0.5)はいくらか。
[3] Zの期待値及び分散を求めよ。
これが問題となります。
まず、
それらの順序統計量をX_(1)≦X_(2)≦X_(3)とする。Y1=X_(1), Y2=X_(2), Y3=X_(3)と置き
この部分で私は???となりました。何言ってんの?と。
X1,X2,X3はそれぞれ確率変数です。確率変数は、前の記事で紹介した通り、「現実の事象を値に変換する関数」でした。つまり、これらの確率変数は実際の値の何かしらを取るわけです。
その結果、X1,X2,X3には大小関係が生じます。X2が一番大きくて、X1が次に大きく、最後がX3などです。どのXが来るかはわからないですが、
一番大きな確率変数X→Y3、2番目に大きな確率変数X→Y2、一番小さな確率変数X→Y1
ということになります。これらを理解して問題に入りましょう。
[1] Y1とY3のそれぞれの確率密度関数f1(y), f3(y)および期待値E[Y1], E[Y3]を求めよ。
まずはそれぞれの確率密度です。一様分布の確率密度となったら、まずは累積分布関数を求めましょう。それを微分したら確率密度関数ですからね。
簡単な方から求めたいため、F3(y)を求めます。
累積分布関数は、ある値以下を取る確率と等しいのでした。つまり、以下で表せます。
F3(y) = P(Y3 ≦ y)
Y3(X1,X2,X3の中で一番大きなX)がy以下の時の確率です。
画像で見ると、こんなイメージ。(今、仮にX2<X3<X1としてます)

この時の確率を求めたいです。
今回複雑なのは、「X1,X2,X3の大小関係が分からない」からですよね。しかし、今回の場合って、それが分からなくても求められませんか?
なぜなら、一番大きいX(Y3)よりもyが大きければいいのです。つまり、X1,X2,X3の大小関係に関係なく、これら3つすべてよりyが大きくなければいけません。
そのため、
F3(y) = P(Y3 ≦ y) = P(X1 ≦ y) × P(X2 ≦ y) × P(X3 ≦ y) = y^3
となります。
それぞれの確率がyになるのは、以下のように、一様分布の面積が確率になることから、1×y=yと求められます。

次は、F1です。こちらはこんなイメージ。

一番小さいXよりも、yが大きい時ですね。普通に考えると、yのエリアはXの大小関係が関係してきそう…。
どうにか、「Xの大小関係に関わらず」出したい!そう思いますよね。
…そんな時は、補集合に目を向けます。この画像のX2以下ではない部分がyですよね。つまりは、その部分を1から引けば、求めたい領域となります。
F1(y) = P(Y1 ≦ y) = 1 - P(X1 ≧ y) × P(X2 ≧ y) × P(X3 ≧ y) = 1 - (1-y)^3
となります。さっきと大なり小なりの向きが逆であることに気を付けてください。
先ほどの面積の図の逆部分の面積なので、(1-y)となりますね。
ここまで求めたら、あとは微分すればOK。期待値も、定義通りの計算で求められます。
[2] Y2の確率密度関数f2(y)を求めよ。また、確率P(Y2<0.5)はいくらか。
これが結構ポイントの問題。先ほどは、うまくXが関係ないように考えて求められました。しかし、今度はY2ということで以下のようなイメージ。

今は仮にX2<X3<X1と置いていますが、それが崩れるとこのyの領域の求め方も異なってきてしまいますね。
ただ、ここでも基本姿勢である「Xの大小関係に関わらないところがないかな」という方針で考えていきます。
すると、このピンクの部分は、結局さっきと同じく大小関係関わらず出せることが分かります。
これは、
P(X1 ≦ y) × P(X2 ≦ y) × P(X3 ≦ y) = y^3
ですね。

次は、この部分です。この間の部分は、Xの順序に関係してきてしまいます。
ただ、今回はX1 ≧ y, X2,3 ≦ y となってますね。この確率は、
P(X1 ≧ y, X2,3 ≦ y) = (1-y)y^2
ですね。そして、Xの組み合わせは他にX2 ≧ y, X1,3 ≦ y と X3 ≧ y, X2,1 ≦ y で合計3通りあります。
(順列で考えると6通りですが、X2,3 ≦ yの部分は1通りなので、全部で3通り)
よって、3をかけて 3(1-y)y^2 となります。

さて、この2つの領域すべてを考えると、上記の2つを足して
y^3 + 3(1-y)y^2
となります。あとはこれを微分です。
確率P(Y2<0.5)は、これも普通に計算すれば求められます。
[3] Zの期待値及び分散を求めよ。
さて最後です。ここにもポイントが1つ。
期待値は、Z=Y3-Y1というところから、
E[Z] = E[Y3-Y1] = E[Y3] - E[Y1]
ですぐに求められます。
分散はこうも簡単にいかないので、
V[Z] = E[Z^2] - {E[Z]}^2 から求めます。2項目は上で出した期待値なので、問題はE[Z^2]です。
さらにZ=Y3-Y1から、
E[Z^2] = E[Y3^2] -2E[Y1・Y3] +E[Y1^2]
となりますね。1項目、3項目は期待値の定義から積分計算で出せますが、2項目の-2E[Y1・Y3]の導出がポイントとなります。
これも定義通り計算するためには、f(y1, y3) という同時確率密度関数が必要になります。
そしてこれを求めるためには、F(y1, y3) という同時累積分布関数を考えます。
F(y1, y3) = P(Y1 ≦ y1, Y3 ≦ y3) となり、イメージはこちら。

この同時確率、明らかにわかりにくいですね。
ただ、y3の方は前と同じようにXの順序に関係なく求められそう。問題はy1の方です。これをどうにか補集合の方に持っていきたいと考えます。
そこで、P(Y1 ≦ y1, Y3 ≦ y3) をこの表のように考えてみます。

この表から、このピンクの部分を求めるために、このように求めてもよさそうなことが分かります。

つまり、このように表せます。
F(y1, y3) = P(Y1 ≦ y1, Y3 ≦ y3) = P(Y3 ≦ y3) - P(Y3 ≦ y3, Y1 > y1)
2項目のP(Y3 ≦ y3, Y1 > y1)の部分のイメージはこちら。

これなら、順番関係なくいけそうです。
X1,X2,X3はy1より大きく、y3より小さいですね。つまり
F(y1, y3) = P(Y1 ≦ y1, Y3 ≦ y3) = P(Y3 ≦ y3) - P(Y3 ≦ y3, Y1 > y1) = P(Y3 ≦ y3) - P(y1 ≦ X1, X2, X3 ≦ y3) = y3^3 - (y3-y1)^3
となります。最後の変形は、一様分布の面積で分かると思います。ここまでくれば計算して、分散を求められます。
さて、一様分布1つをとっても結構とっつきにくいところもあったと思います。
今回のテストでも一様分布についてが出ることを祈りながら、ラスト一週間頑張ります。
日本のウイスキー、山崎と白州(ノンエイジ)飲み比べ
夏の日差しも終わりつつある今日この頃、皆さんいかがお過ごしでしょうか。
さて、久々にウイスキー記事です。
最近、ウイスキーは飲んでいるのですが、大体youtubeを見ながら適当にハイボールを飲むというあまり良くない習慣になってます。
生産性のあることをしたい、そう思って、今回筆を執った次第です。
さて、今回飲み比べたのは、ジャパニーズウイスキーの中でも最も有名であろうこの2つ。

最近コンビニでノンエイジが売られると聞いて、近所のコンビニにいって入手しました。
ジャパニーズは高いので、最近はオールドとリザーブしか飲んでませんが、今回いい機会だったので飲んでいこうと思います。
テイスティング
ストレート
白州は、the洋ナシ。余韻はあっさり目。
山崎は、シェリー感がやはりすごい。ただ、木材っぽい樽感もある。最後の方はちょい苦い、これはワイン樽の影響か?
ちょい加水
白州は、洋ナシ感がマイルドに。より飲みやすくなった感じ。
山崎は、赤い方のリンゴ感。蜜っぽさもわかりやすくなったけど、なんか薄い感じ?
ロック
白州は、おいしいんだが…なんというか、味がつっかえてる感。ストレートの方が、広がってた感じ。
山崎は、ちょうどいい甘さ。後味もしっかり感じる。
総評
全体的には山崎が好き。
白州はストレート、山崎はロックかハイボールが好みだった。
白州のハイボールは、飲んだ時リザーブ味を感じたから、ハイボールはリザーブでいいかな。安いし。
よく、白州はピート感!と聞くが、それを感じられないんだよぁ。自分の中のピート感がおかしいのかも。
山崎のロックとハイボールはうまかったなぁ。これはリピートするレベル。
ただ、前飲んだ山崎12年のストレートはやはりうますぎたから、機械があれば手に入れたい。
山崎は、エイジで使ってる樽が違ったりするらしいので、このノンエイジはロックorハイボール要因としても追加購入してもよいかな。
白州は、自分としてはあまり会わなかった。これならリザーブハイボールでいい感ある。
最近、ジャパニーズのブレンデッドにはまってる。というのも、サントリーのオールドが鬼うまい。安いのに。
水割りに合うと聞いてはいたが、合いすぎ。奇跡のレベル。めっちゃ好き。
ということで、サントリーのオールドとリザーブは買ってちびちび飲んでます。あとはローヤルを買わなくては。
あとは全然地域違って、アイラではアードベッグのウィービースティー(5年)を購入。
美味しいけど、やっぱり10年の柑橘感が足りないなぁと思った。自分は10年の方が好み。
あとは、アードベッグのウーガダールを買いたくて買いたくて、一度カクヤスで買おうとしたら「なんか商品登録されてないので、売れません」
と言われて涙を流しながら帰ってきた。そんなことあります?
総評が長くなった。というわけで、今後もおいしいウイスキーを飲んでいきます。サラダバー。
楽にデータエンジニアリングのレベルを上げてくれるツール、dbtを触ってみた
みなさんおばんどす。夏真っ盛りのお盆ですが、皆さんいかがお過ごしでしょうか。
最近TLなどで、良くdbtというツールを目にします。
データ変換の品質を高める、などという枕詞でよく紹介されていますが、結局のところ何ができるのか?に興味がわいたので、触ってみました。
今回は、dbtの前にそもそもデータエンジニアリングって何だろう?というところから、このdbtについて、さらにはどんな人が使えるのかを考えてみました。
データエンジニアリングってなんだ?
データ分析に少しでも興味ある人なら、聞いたことがあるかもしれません。
「あぁ~、データ加工するETL処理を作ったり、データサイエンティストが欲しいデータをいろんなところから集めたり、ちょっとレベル高くなるとデータカタログ導入したり、データ変換処理のパイプラインを作ったり、ともかくデータを整理する人でしょ?」
と、こんなイメージだと思います。(これでもめっちゃ詳しい人な感じがする)
ただ、ビシッと定義するとなるとその正解はどこにも載っていません。
おそらく、「データエンジニアリングをしよう!」と決めてから誰かがやり始めたというよりは、データ分析をしていくうえでこの部分をやる必要が出てきて、後から名前が付いたからかなと思います。
そこで、まずはデータエンジニアリングとは何か?を簡単に考えてみようと思います。
手掛かりは「エンジニアリング」という言葉。エンジニアリング組織論への招待では、エンジニアリングをソフトウェアについて当てはめたとき、このように述べています。
ソフトウェアにおいても同じことがいえます。それは誰かの曖昧な要求からスタートし、それが具体的で明確な何かに変わっていく家庭が実現で、その過程のすべてがエンジニアリングという行為です。
つまり、「曖昧さ」を減らし、「具体性・明確さ」を増やす行為が「エンジニアリングとは何か」という答えでもあるのです。広木 大地『エンジニアリング組織論への招待』(技術評論社、2018年3月8日初版5刷発行)p.11
つまり、データエンジニアリングは、データにおいて「曖昧さ」を減らし、「具体性・明確さ」を増やす行為だと言えそうです。
データにおける曖昧さとは、私が考えうる限りだと
・日々変化していくデータ
・口頭伝承されていくテーブル、カラムの意味
・誰が作ったか分からない加工済みのテーブル
・ソース元不明のマスタデータ
などがありそうです。これらを減らして、具体性・明確さを増やす行為が、データエンジニアリングなのではないでしょうか。
私が触った限りだと、dbtは上記の曖昧さを「必要最低限の労力で」具体的にするツールだと思いました。
そこで、タイトルのような紹介をしたというわけです。
dbtとは?
DWHに格納されているデータを加工したいとき、SQLを書くと思います。
そのSQLを書くのを支援し、かつそのSQLで出来たテーブルのテストをし、かつカタログ的な機能(カラムにコメントや、SQLを自動で読み込んでリネージ)もあるツールです。
ただし、エンジンを持つDWH(SnowflakeやBigQueryなど)を使っていることが前提です。SQLを実際に動かすエンジンは、dbtではなくDWH側となります。
どの場所を担うかは、以下の図が分かりやすいです。

いつもはDWH側で書いていたSQLを、代わりにこのdbt上で書くというイメージです。
CUI版とGUI版があり、CUI版はOSSとして無料で使えます。GUI版は1人で使う分には無料ですが、チームやエンタープライズとして使うと有料です。
(1人だと無料なので、試しに動かしてみるのはデモやトライアルではなく通常版でずっと使えます)
dbtを導入した時の作業イメージ
SQLを書いて加工後データを作成する
これは、dbtを導入しなくてもやる行為です。
ただ、dbtでやることによって、よく使うSQLをマクロとして保存して使えたり、PythonのライブラリであるJinjaが使えたりします。
とりあえず、自分でSnowflakeと接続して、SQLを書いてみました。

これは、購買履歴テーブルに顧客マスタをjoinして、顧客の年代別に売り上げの集計をしたテーブルです。
ここで注目してほしいのは、改行とかインデントとかが汚いところではなく、INNER JOINの次のref( )式です。
このref内のcustomer_masterは、dbt内で定義しているテーブル名です。つまり、実際のSnowflakeのテーブル名は知らずとも、dbt内で定義しているテーブル名を知っていればSQLが書けるということです。
これによって、元のテーブルが変わってもdbt内で定義しなおせば影響を受けないというメリットのほか、あとで紹介するリネージ機能にも使われます。
このSQLをdbt上で実行すると、裏でSnowflakeのエンジン(ウェアハウス)が実行され、以下のようにSnowflake側にテーブルができています。

テストを書いてチェックする
テストをyamlファイルで簡単に定義できます。

5行目と14行目から、それぞれ別のテーブルに対するテストを定義しています。
先ほど見せたテーブルは14行目以降です。
テストとは関係ないですが、15行目のようにdescriptionにコメントを書いておけば、あとでドキュメントに反映されます。
17行目からは、カラム名「AGES」のテストです。
testsに「not_null」を指定することで、このカラムにnullが入らないことを定義しています。
また、「accepted_values」を指定することで、22行目に記載された値しかそのカラムが取らないことを定義しています。
ここは年代のカラムなので、0から90の10刻みの値しかとりません。
そのほかにも、そのカラムの値がユニーク値を取るかどうかのテストができます。
それ以外のテストは、自身で定義する必要があります。詳しくは以下の公式docに詳しく乗っています。
Tests | dbt Docs
さて、上記のyamlファイルを作成して、テストコマンドを実行すると実際にテストします。

今回は2つのカラムに対して3つのテストをして、全てOKだという結果になりました。
自動化もできるので、日次で更新される元データに対して、SQLとテストを実行すればデータに対して自動テスト実行が可能です。
dbtを導入して得られるメリット
データに対するテストを実行できる
やはりメインはこれですね。
ユニークチェック、Null値チェック、具体的な値のチェックであればyamlファイルに1行書けばできてしまうので、かなり楽です。
今回はやっていませんが、テスト内容も独自定義できるので、よくやるテストは一度書けば再利用可能です。
ETL処理の再利用というのは、意外となかなかハマらないことが多い(それぞれやりたいことが違うため)ですが、個人の経験上データに対するテストは大体同じことをやっています。
そのため、テスト処理の再利用は効果的であると思いました。
ドキュメントが自動作成される
これもかなり良いと思います。
先ほどのyamlファイルで、テーブルやカラムに対してdescriptionを記載しました。それを自動で拾ってドキュメンテーションしてくれます。

テーブル、カラムのコメントが反映されているのが分かります。
また、カラムの型はSnowflake側の定義から勝手にとってきてます。
実行しているテストも書いてあるので、どんな品質チェックを受けてるかも確認できます。
ここでは見えていませんが、このテーブルを作成しているSQLもわかるため、なにか自分の分析に不都合な処理がされていないかも確認できます。
このドキュメントで私がすごいと思ったのは、リネージ機能です。
先ほどのdoc画面の右下の青いボタンをぽちっと押すと、リネージ画面が出てきます。

これは、SQLの中のref文を拾ってグラフにしてます。
現時点では2つしかないので寂しい感じですが、実際の現場では複数のテーブルが参照されまくっているはずなので、大きな地図ができるはずです。
ここまでの機能で、ほぼデータカタログツールの代わりになります。
SQLやyamlファイルの構成管理ができる
最近のツールは組み込まれていることが多いですね。Looker然り。
画面上に「commit」ボタンがあるため、変更があればすぐにコミットできてしまいます。
また、この記事を見ると、commitしたときに、自動でSQLを実行、かつtestも実行して、OKならマージするというCI構成も簡単にできるそうです。すごい。
[dbt] CI(継続的インテグレーション)を取り入れる | DevelopersIO
どんな人に向いているか?
私がdbtの利用に向いていると思うのは
クラウド型DWH(SnowflakeやBigQuery)を利用している
AND
(運用中のETLパイプラインが増えてきて、日々の障害が出始めてきたデータエンジニア
OR
人が増えてきて、そろそろ全員の分析に使うデータを見切れなくなってきたチーフデータサイエンティスト)
です。
ここまで紹介した通り、dbtはSQLを書く作業自体がめちゃくちゃ楽になるわけではありません。(マクロやJinjaで楽に書けるようにはなりそうだけど)
そのため、「いつも書いてるSQLをもっと楽にかきたいぜ!」という人には向きません。
逆に、テストやドキュメント化はかなり楽に行えるため、データや人が増えてガバナンスを効かせたくなっている人に向いています。
ここで、データや人が増えるとはどういうことかを今一度考えてみると、結局は「不確実性が増える」ということではないでしょうか。
dbtに限らず、データや人が増えると不確実性が増えるため、何かしらの対策を講じないといけなくなります。
その対策がデータエンジニアリングであり、それを楽に行えるのがこのdbtというツールであると私は思います。
確率変数について超わかりやすく説明する
皆さんこんにちは。空には入道雲が広がり、暑さも続く昨今、いかがお過ごしでしょうか。
まえがき
私はというと、いつもの発作がおきまして、統計について勉強しなおしています。
いつも統計の勉強をしていて思いますが、最初に出てくる確率変数の概念がいまいちしっくりこない。
だから、そこから続く式も頭に入ってこない。とりあえず式の形や定義を覚えて、1か月後には忘れる。
それを何回も繰り返していました。
しかし、今回、確率変数のしっくりくる説明を見つけ、かつそこからつながる累積分布関数、確率関数、確率密度関数が
ストーリーとしてわかるようになりました。ちょっと感動したので、それを忘れないためにもここに記載しておこうと思い立ったわけです。
今回は、一旦確率変数の説明のみをします。これがわかれば、それ以降の累積分布関数などは書籍の説明で理解できると思います。
ということで、さっそく始めます。
確率変数とは?
私が買った参考書には、以下のように説明されています。
一般に、Ωを全事象、ΒをΩの可測集合族、Pを(Ω, Β) 上の確率とするとき、ω∈Ωに対して実数値X(ω)∈Rを対応させる関数Xを確率変数という。
ただ、これではさっぱりわかりません。
そのため、私が色々調べたり考えたりした結果、このように理解するのが一番わかりやすいという結論に至りました。
確率変数とは、事象を実数値に変換する関数である。
まず、確率変数とは関数です。一般的な関数は、f(x)=x+3のように、「ある値を入れると、なにか別の値が返ってくる」というものです。
しかし、確率変数は、「ある事象を入れると、なにか実数値が返ってくる」という関数なのです。
例を用いて説明します。

例えば上図のさいころの例です。
「さいころを振って5が出た」という事象に対して、5という実数値を返すのが確率変数Xです。
ここで、「さいころの目が5なんだからそれに対応するのは5で当たり前じゃないか」と思うかもしれませんが、
さいころの目が5であることとそれに対応する実数値が5であることは別物です。
例えば、ヘブライ語で5は ה です。さいころに ה と書いてある目が出たらどうでしょうか。
これが5に対応するか、知らないとわかりませんよね。
このように、
この現実世界で起きた事象を、計算できるように数値の世界に変換する
のが確率変数Xです。
また、右2つの身長の測定や時間の計測も同じように考えられます。
ただ、こちらはさいころやコインと違って、実数値が無限に存在します(163.0cm, 163.0000000000000001cm, 163.00022101031cm など)。
言い換えると、実数値が飛び飛びではなく連続して存在するので、この時の確率変数を連続型確率変数といいます。
そして、左2つのさいころとコインのように、実数値がとびとびの時の確率変数を、離散型確率変数といいます。
確率変数と確率の関係は?
確率変数についてわかったところで、この確率変数と確率Pの関係について考えます。
これも、まずは私の読んでいる参考書から引用します。
任意の実数xに対してX≦xである確率は
として,(Ω,Β)上で定義された確率Pを用いて与えることができる.
久保川達也『現代数理統計学の基礎』(共立出版、2020年7月5日初版7刷発行)p.11
ぱっとみイカつい式ですが、先ほどの「確率変数とは、事象を実数値に変換する関数である。」ということが分かれば理解できます。
左辺は分かりやすいと思います。任意の実数xなので、例えばさいころを振った時のことを考えるとして、xを3としましょう。
そうすると、P(X≦x)は、「確率変数の値が3以下の時の確率」という意味になります。
次は右辺ですが、まずこの縦棒|は条件付き確率を示します。
例えば、A,B,Cという3つの袋があって、それぞれの袋に赤球と白球が入っていたとします。
その時、袋Bを選んだ前提で、赤球を引く確率を
P( 赤球 | 袋B )
と表せます。つまり、縦棒|の右側を前提として、左側の事象が起きた時の確率を示しています。
元の式の右辺に戻って、まずは縦棒|の右側である前提条件から見ていきます。
X(ω)≦xですが、まずωはある事象です。さいころで5の目が出る、コインを投げて表が出る、身長を測って163cmだった、時間を計って12.3秒だった、などです。
それを確率変数Xに入れたX(ω)は、先ほどの絵で言うところの下側、実数値になりますよね。
つまり、ここは「実数値がx以下になるとき」という前提条件になります。
さいころを振った時のことを考えて、xを3とした場合は、「実数値が3以下になるとき」となります。
さて、次は縦棒|の左側です。
ω∈Ω となっています。ここでΩは、全事象を示しています。さいころ振りで言えば、1~6の目が出る全てですね。
そのため、ここは「全事象に含まれるある事象」と言っているわけです。
これらを総合すると、
この式の右辺は「実数値があるx以下になるという前提条件のときの、(全事象に含まれる)ある事象」と翻訳できます。
縦棒|の右側は実数値(絵の下半分の数値の世界)で前提条件を指定していて、左側はその前提条件における事象(絵の上半分の現実の世界)を言っているのです。
そう考えると、左辺と右辺は同じことを言っていることが分かりますよね。
このように、確率変数が絡んできている式の時は、現実の世界か、数値の世界どちらのことを言っているのか?と考えるとしっくりくると思います。
まとめ
- 確率変数とは、事象を実数値に変換する関数である。
- 実数値がとびとびの場合は「離散型確率変数」、連続の場合は「連続型確率変数」という。
- 確率変数と確率の関係も、現実の世界での事象の話と数値の世界での実数値の話を踏まえると理解しやすい。
以上です。
素人が勢いで書いた記事のため、間違いなどあったらご指摘いただけるとありがたいです。
引き続き、この本は読んでいこうと思います。
")
Coleridgeコンペ参戦記
約2週間ほど前になりますが、取り組んでいたColeridgeコンペが終了しました。
結果は残念なものでした(Public:163/1610 → Private:510/1610)が、記録として振り返っておこうと思います。
コンペ概要
様々な分野の論文のテキストデータが与えられて、その中からデータセット名を特定します。
トレーニングデータとして1つの論文のテキストデータが1つのjsonとして与えられていて、そのjson1つに対して複数の正解ラベル(データセット名)が与えられます。
例えば、実際のトレーニングデータの一部で以下のテキストがあります。
Any college degree attainment The study author collected information on college degree attainment from the fourth follow-up of the National Education Longitudinal Study collected in 2000.
この太字で示しているNational Education Longitudinal Studyが正解ラベルのデータセット名です。
テストデータはこのテキストだけが与えられていて、その中からデータセット名を当てる必要があります。
ただ、今回のコンペはCodeコンペなので、テストデータはほとんど隠されています(手元に与えられるテストデータは4つのjsonだけ。実際はPublicは約1000、Privateは約8000ほどの論文が与えられます)。
やったこと
今回はメモ程度の日記をつけながらやったのでいろいろと記録してあります。
まず、今回のコンペで費やした時間は78時間でした。
(それでこの体たらくかよ、というツッコミは置いておいて…)
前半戦-自力でモデル構築
前半は、ほとんどNLPのコードをまず動かすことに使ってました。
ちょうどこの本を持っていたので、この本の実装を今回のコンペに当てはめて動かしていました。
")
今回のコンペの問題は、固有表現抽出が使える!と考えたので、Chapter10を読んで実装しました。
固有表現抽出とは、こういうやつ。(wikiより)
固有表現抽出(こゆうひょうげんちゅうしゅつ、英: named entity recognition、named entity identification、named entity chunking、named entity extraction)とは、計算機を用いた自然言語処理技術の一つであり、情報抽出の一分野である。文中から固有表現 (Named Entity) を抽出し、それを固有名詞(人名、組織名、地名など)や日付、時間表現、数量、金額、パーセンテージなどのあらかじめ定義された固有表現分類へと分類する。
テキストデータの中のデータセット名を固有表現としてラベリングしておけば、このタスクで解けるじゃないか!
ということです。
Discussionみても、ところどころ使っている人はいたので、それなりに筋はいいかなと進めていました。
LSTMモデルを使う方法と、その次にBERTを使う方法を試して、初SUBできた時点で32時間経過でした。
内容は本がわかりやすかったですが、サイトではここら辺がわかりやすい。
hironsan.hatenablog.com
テキストを自分でラベリング(単語ごとに、「これは固有表現」「これは違う」のラベリング)しなくてはいけないのと、モデルに合わせて単語をベクトル化したりトークン化(英単語を数字へ)したりしなくてはいけないので、前処理が結構面倒でした。
ただ、前者はやってくれているKernelがあり、後者はtransformerのメソッドが存在する+本から丸パクリで何とか実装しました。
今後もここで書いたコードは使えそう。
後半戦-モデル、後処理の改善
後半は、この実装したモデルとテキストマッチングを合わせてsubをしていきました。
今回、機械学習で正解を当てるほかに、「世の中のデータセット名を頑張って集めてきて、それらとテキストマッチングさせる」というテキストマッチング手法が流行りました。
ただ、コンペ主催者から、「使ったサイトは公表するように」とあったため、additionalなデータセット名は公開されてました。
そのため、論文ごとにそのデータセット名とマッチングさせて、そのマッチングが0なら機械学習で推定するという方法がKernel内では流行ってました。
他にも、機械学習で出した答えとこのマッチングの結果のORを取るとか、ANDを取るとか、条件付きでANDを取る(類似度が低いもの限定)とかやってみましたが、
上記の方法が一番PublicScoreが高くなりました。
と色々書きましたが、結果的に一番PublicScoreが高かったのは公開Kernelを使ったものというオチでした。笑
自分で学習させたモデル+テキストマッチングは、どうやってもスコアかなわずとなりました…。
(fold=3でCrossValidationさせたりと色々してスコア自体は上がっていったのですが、どうやっても公開カーネルには届かず。)
最終的には、
・PublicScoreが一番高い公開Kernel
・テキストマッチングはしないで、自作のモデルで推論した結果だけのもの
以上の2つをSubとして提出しました。
2つ目は、Privateにテキストマッチングするものが少なかった時にShakeが起きるだろうと予測して、一応選びました。
公開Kernelのモデルだけを使った方がよいのでは?とも思いましたが、選べなかったときに後悔する度から自作のモデルを選びました。笑
結果、Privateではどちらもスコア振るわずとなりました。
大切だったこと
コンペ終了後、Discussionや個人ブログやtweetなどを読み、大切だと感じたのは、以下2つです。
① トレーニングデータには、未知の正解ラベル(データセット)が存在している。
② テストデータ(Public)にはトレーニングデータと同じ論文が含まれている。(≒テストデータ(Private)にはほぼ含まれていない)
①は分かりにくいので、図を描きました。
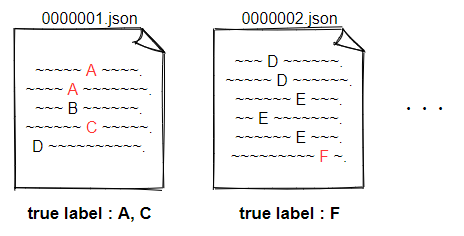
トレーニングデータには、jsonに対応して正解ラベルが付与されていますが、全ての正解ラベルが付与されているわけではないということです。
例えば図の0000001.jsonは、実際の正解ラベルはA,B,C,Dの4つですがトレーニングデータとしてはA,Cの2つしか付与されていない、ということが起きています。
これのせいで、トレーニングデータのラベルをそのまま使って学習させても、良いモデルができません。
どれだけ良いモデルを使っても、学習時に「正解ラベルはA,Cだぞ!」と学習させたら、BとDは推論できないですからね。
私が作ったモデルがダメだったのは、これを考慮せずに学習させていたからだと思われます。
他の方々を見ると、まずは正規表現などで未知の正解ラベル(データセット)を当てに行く手法が多かったです。
例えば、正解ラベルを見ていくとデータセット名はすべて1文字目が大文字であったり、データセット名の後にカッコで略称が入っていたりするものが多いです。
それらをルールベースで見つけていく、という機械学習は使わない方法です。
それで見つけたものをさらに学習データとしてモデルを構築するという人が多かったです。
②は、今回のfinalSubの選択基準に大きくかかわるところでした。
これはコンペのDataタブの説明欄に書いてあったことです。
A percentage of the public test set publications are drawn from the training set - not all datasets have been identified in train, so these unidentified datasets have been used as a portion of the public test labels.
このため、いくらPublicでスコアが高くてもそれは「トレーニングデータで出てきている正解ラベルを当てただけ」という可能性が出てきます。
この影響をなくして、Privateのスコアの高さを見るには、最終的な推論結果からトレーニングデータの正解ラベルを削除してsubmitすることが必要です。
こうすれば、純粋に未知のラベルをどれだけ当てているか?を判断でき、Privateと同じ状況となります。
実際、LateSubmitでいくつか試してみましたが、以下のような結果となりました。
public : private : public(delete train labels)
0.576 : 0.195 : 0.182
0.574 : 0.226 : 0.214
0.545 : 0.246 : 0.237
見事に、今回の正解ラベルを削除してsubmitしたスコアとprivateスコアの大小関係が一致しています。
逆に、ただsubmitしただけのスコア(一番左)はprivateとは逆転していますね。
これは、この方の書き込みからわかりました。
この方の出しているKernelも読みましたが、とてもすごい。
既知のラベルがpublicにも含まれているというところから、テストデータには1つのjsonファイルに平均10個の正解ラベルがあるということを導出されています。
トレーニングデータは平均1個ちょいなので、テストデータにはかなり未知のラベルが多いことになります。
よってsubの推定結果から既知ラベルを全て除いた上でpublic scoreが最も高いモデルを採用すればprivateに最適なsubが作れると分かっていた。
— OsciiArt◆SPNEXTcRxQ (@osciiart) June 23, 2021
MLMモデルについて
ちょっと話は飛んで、使用したモデルについてです。
私は固有表現抽出モデルを作りましたが、KernelではMLMモデルが流行っていました。
テキストのある部分をマスクして、そのマスク部分の単語を機械学習で導出するというモデルです。
まずはデータセット名っぽいところ(単語の1文字目が大文字か、inなどの前置詞のもの)をマスキングして、それがデータセット名かを予測させるモデルでした。
学習kernel
[Coleridge] BERT - Masked Dataset Modeling | Kaggle
推論kernel
[Coleridge] Predict with Masked Dataset Modeling | Kaggle
こちらのモデルはPrivateでもスコアが落ちることなく優秀で、自分の提出したカーネルのモデル部分をこれに置き換えるだけで、銅メダルスコアが出ました。
学習の中で、ただ正解ラベルをインプットにしているだけでなく、「データセット名っぽいところ」もインプットにしているため、これが
「① トレーニングデータには、未知の正解ラベル(データセット)が存在している。」の対策になっていたのではないかと思います。
ただ、いくつかわからない点もありました。
・学習時、正解ラベルを渡していないように見える。どうやって学習させている?
・推論した結果がネガティブデータ(データセット名ではないもの)であっても予測結果に加えているように見える。なぜ?
ここは正直よくわかりませんでしたが、上記の理由からスコアが落ちなかったのではないかなと思います。
今回のコンペの学び
・train、test(public), test(private)のデータはどのように分けられているかをもっと調べよう。
・データを見て、方針を立てよう。(正規表現で行けるんじゃないか?など)
・DeepLeraning系のコンペでは、モデルはkernelで出ているやつをまず使おう。自作はその次。
…当たり前のことをしっかりやる。次は勝つ。以上!
参考
以下の2つのブログは振り返るうえで非常に参考になりました。
やっている内容も私より全然高度で、かつブログとしても読みやすい。
kaggle、ナニモワカラナイのレベルにいるなと改めて実感しました。。
【Kaggle】 Goldを目指したけど、木っ端微塵に砕け散った話|しょーた|note
Kaggle Coleridge 52nd solution - 情報系院生のノート