HBase触ってみた
皆さんこんばんは。花粉が舞いに舞っている昨今、いかがお過ごしでしょうか。 春といえば、OSSのDBが恋しくなります。ということで、HBaseを今日一日触っていたので、その記録を書こうかと思います。
というのも、オライリーのデータ指向アプリケーションデザインの第6章「パーティション」を読んでいて、実際にプロダクトを触りたくなってきたからです。
データを分散して分けた1つ1つをパーティションと呼び、それをどのように分けるか?はたまたどのようにリバランシングするか?
などが載っていました。概念は理解しましたが、実際に実装だとどういう感じなのか理解したかった次第です。
HBaseとは?

- ApacheのOSSのプロダクトのうちの1つ。
- HDFS(Hadoop Distributed File System)上に構築するデータベース。
- HDFSは、Hadoopに使われる分散ファイルシステム。いい感じに分散してファイルを保存する。
- NoSQLの中のワイドカラム型に属する。
- キーバリュー型の拡張。1つのキーに対して複数の列を持つことができる。
- Regionという単位でデータを分散して持つ。そしてそのRegionをスレーブノードに割り当てる。
- スレーブノードは他のPC1台に当たる。つまり、PC1台を追加する(スレーブノードを追加する)と、Regionが新たに割り当てられてスケールアップする。
HBaseの概要とアーキテクチャ | Think IT(シンクイット)
ここを読めばかなり詳しくわかります。
いわゆるMPP(Massively Parallel Processing)はRDBMSが並列処理を可能にしたものだけど、それとはまた別流派の分散DBといった感じでしょうか。
とにかく、パーティションを実現できるOSSなので、HBaseを今回は触ってみたいと思います。
HBaseのインストール
環境
Windows10
Docker version 20.10.5
docker-compose version 1.29.0
上記のWindows端末で実行していきます。
DockerでHBaseのコンテナ作成
① 資材をcloneしてくる
GitHub - big-data-europe/docker-hbase
上記のリポジトリをcloneしてきましょう。
Windowsでのgitのインストールはここなど詳しいです。
【Windows】Gitの環境構築をしよう! | プログラミングの入門なら基礎から学べるProgate[プロゲート]
ちなみに、以下の2つがdocker-composeファイルです。
今回は、分散処理させてみたかったので「distributed-local」の方を使います。
・docker-compose-distributed-local.yml
・docker-compose-standalone.yml
② ビルド実行
cloneした場所にPowerShellで移動して、以下を実行します。
docker-compose -f docker-compose-distributed-local.yml up -d
これでymlファイルに記載されているコンテナが複数ビルドされ、さらに立ち上がるはずです。
私はこれとは別にDocker Desktopも入れていますが、それ上ではこのように見えています。

③ WEB UIで確認
http://localhost:16010
にアクセスしてみましょう。
上手くHBaseが立ち上がっていれば、以下のような画面になります。
(テーブルやRegion数はいじった後なので、立ち上げ直後とは異なると思います)

参考
以下のページを参考にしました。
docker composeを使って「hbase」を構築するまでの手順 | mebee
HBaseのインストールと実行方法(スタンドアロンモード) - TASK NOTES
HBaseでのテーブル作成
テーブル作成、データ挿入
① コンテナログイン
マスターノードにログインします。「hbase-master」がマスターノードのクラスター名です。
docker exec -it hbase-master /bin/bash
② hbase-shell起動
(ここからはマスターノード上でコマンド実行します)
ログイン出来たら、以下のコマンドで対話型のコマンドラインツールを起動します。
hbase shell
次からは、このツール上でhbaseに色々なコマンドを打っていきます。
③ テーブル作成
create文でテーブルを作成します。
create 'テーブル名', 'ColumnFamily名' です。
create 'test_table', 'cf'
④ テーブル確認
WEB UI上で確認します。
以下のように、新しいテーブルができていれば成功です。
このテーブルは、Online Regionsがまだ1なので、分散されていない状態ですね。

⑤ データ挿入
put文でデータを挿入します。
put 'キー名', 'ColumnFamily名:Column名', 'バリュー' です。
put 'test_table', 'row1', 'cf:col1', 'value1'
このあたりの関係性は、以下のページが分かりやすいです。
HBaseのアーキテクチャを理解しよう (1/3):CodeZine(コードジン)
⑥ データ確認
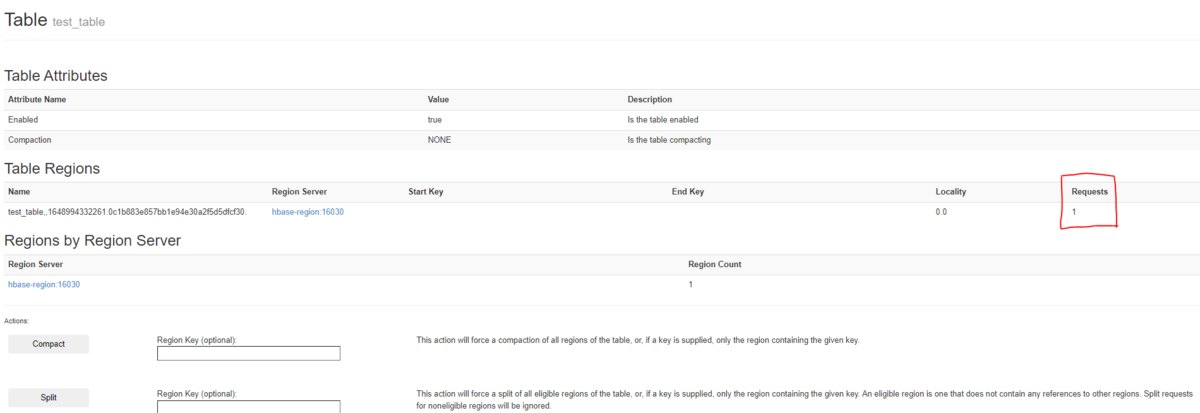
WEB UI上で、Tableをクリックすると以下の画面に遷移します。
赤枠で囲っている、Requestsが1になっていればデータが挿入されています。
(「scan 'table名'」をhbase shellで打っても、データの内容は確認可能です)
HBaseでのパーティション確認
さて、ここからが本題。パーティションです。
事前パーティション
① 事前パーティションを定義してテーブル作成
以下のコマンドで、新しいテーブルを作成します。
今度は、キーの範囲でパーティションを切るように指定しています。
create 'test_table2', 'cf', SPLITS => ['1000','2000','3000','4000']
② 確認
WEB UIで確認します。
~1000 / 1000~2000 / 2000~3000 / 3000~4000 / 4000~
の5つのパーティションが作成されていることが分かります。

③ データを挿入
1000~2000のパーティションにデータを挿入してみます。
今回は、キーを'1234'にしてみましょう。
put 'test_table2', '1234', 'cf:col1', 'value1'
④ 確認
WEB UIで見ると、ちゃんと想定のパーティションのRequestsが1となっていますね。

パーティションの強制分割
ここでは、今5つに分けられているパーティションのうちの1つを強制的に分割してみます。
以下のページを参考にしています。(ちなみに、強制マージはできないそうです)
Apache HBase Region Splitting and Merging - Cloudera Blog
① 分割
ここでは、split文を用います。
split '8efadd362101393ea6e29e7cc7ee3fd0'
split 'encoded region name'
とすることで、指定のパーティションが分割されます。
'encoded region name'は、テーブル名とパーティションの開始の値(1000など)とtimestampのハッシュを取ってエンコードされたものだそうです。
参考:HBase hbckについて その1 - Qiita
'encoded region name'は、WEB UIだとここに表示されています。

② 確認
WEB UIで確認してみますが…
変化がないです。なぜかパーティションが分割されていませんね。
データ量が少なすぎた?少し大きいデータをいくつか挿入してみましょう。
③ データ挿入
以下のput文を、キーの値が1100, 1300, 1600, 1900の4種類ごとに10回打ちました。
100万文字は半角数字だったので、1回につき約1MBですね。
そのため、全部で40MBのデータを挿入した計算になります。
put 'test_table2', '1100', 'cf:col1', '[100万文字]'
さて、これでsplitを再度打ってみましょう。
(一応、split打つ前はこんな感じ。Requestsが44に増えてます)

④ splitと確認
前と同じsplit文を打ちます。
split '8efadd362101393ea6e29e7cc7ee3fd0'
結果はこちら。

見事に2つに分かれている…が、分割しているキーの範囲が何かおかしい?
1100, 1300, 1600, 1900に分けたので、1500くらいで分割されてくれると思いましたが。。
これは原因不明です。わかる方いたら教えてください。
自動パーティション分割
こちらは、HBaseのver0.94以降では、
Min (R2 * “hbase.hregion.memstore.flush.size”, “hbase.hregion.max.filesize”)
この式を超えると自動で分割されるそうです。
この2つは設定値で変更可能です。
・"hbase.hregion.memstore.flush.size”
・“hbase.hregion.max.filesize”
また、Rは同じテーブル内の現在のリージョンの数。
例えば、まだ1個しかリージョンが割当てられていない状態で、"hbase.hregion.memstore.flush.size”が128MBだとすると、その時は128MBを超えたら分割されます。
次は、2個割り当てられているのでRは2です。そのため、22 * 128MB=512MB を超えたら分割されます。
本当はこれを試してみたかったですが、このサイズのデータを挿入するのがかなりしんどいため見送りました。
どなたかやってみてください。
まとめ
- HbaseはOSSの分散データベース。
- docker-composeを使って簡単に構築可能。
- テーブル作成の際にパーティションを指定できる。
- splitコマンドで強制的に分割できる。
- なぜかきれいなパーティション範囲で分割できず。
- 自動分割も可能。設定値を変更すれば閾値も変えられる。
OSS知識欲が出てきたため、Sparkなども触ってみたいですね。
それでは。
入門 Avro 第2版
オライリーっぽいタイトルつけてみました。こんにちは。
最近はダラダラと過ごしてしまっていますが、今回はApache Avroをちょっと触ってみたのでその記事を書こうと思います。
Avroとは?
効率的にデータが保存できる、バイナリのフォーマットです。
いわゆる行指向フォーマットというやつで、OLTP処理の場合に向いているフォーマットとのこと。
そのあたりの全体像はこのブログが詳しかったので、ぜひ。
カラムナフォーマットのきほん 〜データウェアハウスを支える技術〜 - Retty Tech Blog
また、こちらの本
の中には、
Avroにおいて鍵となる考え方は、ライターのスキーマとリーダーのスキーマは同一である必要がなく、互換性さえあればよいという考え方です。
とあります。
つまり、スキーマ定義(このデータは"Name”(String)、"Age"(int)という列を持っているぞ!のようなもの)がライターとリーダーで別々で持てるということです。
(互換性は持っておく必要あり)
別々で持てると、例えば「次のアプリからは今まであった"Age"ってカラムいらなくなったんだよなぁ~」というときは、リーダーのスキーマ定義だけ変更するとかの対応ができますよね。
スキーマの進化に対して、修正のハードルが低いんですよ、という内容が載っていました。
と、ここまで読んだら、実際にコード書いて確かめたくなりますよね。
というわけで、実際にpythonで書いてみました。
まずは公式チュートリアル
Apache Avro™ 1.11.0 Getting Started (Python)
とりあえずここに書いてある内容を読んで動かせば、avroファイルの書き込み、読み取りのイメージはつかめます。
ただ、
- コードと説明が背景同じで書かれているのでどの部分がコードなのか分かりにくい
- python3の実装と書いてあるのに、print文の書き方が2系(print("aaa")ではなく、print "aaa"になってる)
という罠があるので気を付けてください。
一応、ここからはチュートリアルの内容を見ていきます。
以下、チュートリアルのコードを私が見やすいように整形したものです。
・pythonコード
import avro.schema from avro.datafile import DataFileReader, DataFileWriter from avro.io import DatumReader, DatumWriter def avro_write(write_file, schema): writer = DataFileWriter(open(write_file, "wb"), DatumWriter(), schema) writer.append({"name": "Alyssa", "favorite_number": 256}) writer.append({"name": "Ben", "favorite_number": 7, "favorite_color": "red"}) writer.close() def avro_read(read_file): reader = DataFileReader(open(read_file, "rb"), DatumReader()) for record in reader: print(record) reader.close() write_file = "users.avro" read_file = "users.avro" schema = avro.schema.parse(open("user.avsc", "rb").read()) avro_write(write_file, schema) avro_read(read_file)
{"namespace": "example.avro", "type": "record", "name": "User", "fields": [ {"name": "name", "type": "string"}, {"name": "favorite_number", "type": ["int", "null"]}, {"name": "favorite_color", "type": ["string", "null"]} ] }
単純に、書き込みと読み込みを行っています。
このpythonファイルを実行すると、実行結果はこの2行です。
{'name': 'Alyssa', 'favorite_number': 256, 'favorite_color': None}
{'name': 'Ben', 'favorite_number': 7, 'favorite_color': 'red'}
Alyssaの"favorite_color"は、python内の書き込みで指定していないため、結果出力ではNoneになっていますね。
これは、スキーマ定義で"favorite_color"のtypeに"null"が含まれているためです。
試しにスキーマ定義の"null"を削除してみると、エラーが返ってきました。
さて、基本的な読み込み書き込みはこれで私も理解したのですが、ここで1つ疑問が。
書籍内では、リーダーとライター別々のスキーマ持てるって聞いたけど、このチュートリアルだとライターしかスキーマ定義使ってなくね?
ということです。
確かに、読み込みの時はスキーマを使わなくても読み込めています。
どうやら、読み込みの時何も指定しなくても、ライターの定義を内部で保持していて、それを勝手に使ってくれるようです。
ただ、どうせなら別々のスキーマ定義使いたい!ということでその実装方法も調べてみました。
ライターとリーダーで別々のスキーマ定義を使ってみる
まずは、使うスキーマ定義を。
v1として前使っていたものと同じスキーマ、v2としてその中の"favorite_color"を落としたものを使います。
そして、ライターではv1、リーダーではv2を使ってみます。
つまり、ライターの時はfavorite_colorが定義されているからデータとしても書き込まれているけど、
リーダーの時はfavorite_colorを無視したい!というユースケースですね。
・スキーマ定義_v1(user_v1.avsc)
{"namespace": "example.avro", "type": "record", "name": "User", "fields": [ {"name": "name", "type": "string"}, {"name": "favorite_number", "type": ["int", "null"]}, {"name": "favorite_color", "type": ["string", "null"]} ] }
・スキーマ定義_v2(user_v2.avsc)
{"namespace": "example.avro", "type": "record", "name": "User", "fields": [ {"name": "name", "type": "string"}, {"name": "favorite_number", "type": ["int", "null"]} ] }
では、使うpythonコードです。
変更点は、リーダーにもスキーマを使うようにしたところです。
そのやり方がどこにも書いてなかったので結構てこずりましたが、頼るべきものは公式。
avro/io.py at release-1.7.7 · apache/avro · GitHub
上記の実際のavroのpython実装を見ると、DatumReader()のinitにこんなものが書いてあるじゃないですか。

確かに、さっきまでの公式チュートリアルだとDatumReader() と引数なしで使っていた。
なので、リーダーのスキーマだけ指定するように
DatumReader(None, reader_schema)
という感じに使ったら、見事動きました。
以下、完成品です。
import avro.schema from avro.datafile import DataFileReader, DataFileWriter from avro.io import DatumReader, DatumWriter def avro_write(write_file, schema): writer = DataFileWriter(open(write_file, "wb"), DatumWriter(), schema) writer.append({"name": "Alyssa", "favorite_number": 256}) writer.append({"name": "Ben", "favorite_number": 7, "favorite_color": "red"}) writer.close() def avro_read(read_file, schema): # ここでリーダーのスキーマ定義を使う reader = DataFileReader(open(read_file, "rb"), DatumReader(None,schema)) for record in reader: print(record) reader.close() write_file = "users.avro" read_file = "users.avro" schema_v1 = avro.schema.parse(open("user_v1.avsc", "rb").read()) schema_v2 = avro.schema.parse(open("user_v2.avsc", "rb").read()) avro_write(write_file, schema_v1) avro_read(read_file, schema_v2)
実行結果はこちら。
{'name': 'Alyssa', 'favorite_number': 256}
{'name': 'Ben', 'favorite_number': 7}
見事、リーダーのスキーマ定義だけ落とした"favorite_color"が出力されていませんね。
これで、明日から急にAvroで別々のスキーマ定義したいといわれても対応できます。
アードベッグ10年とアードベッグコリーブレッカン飲み比べてみた
ボンジョールノ!supa25です。
今日は、私が愛してやまないアードベッグ10年と、シリーズの中でも最もスモーキーといわれるコリーブレッカンを飲み比べしてみようと思います。
この前、10年飲んでて色々調べていたら、気づいたらぽちってたのがコリーブレッカンです。
前も一度買ったことあるのですが、あの時とは感覚も違うだろうと再チャレンジしたものになります。

相変わらずジャケ写はかっこいい。
コリーブレッカンは、渦のようなアイコンが右下に見えますね。
そもそもコリーブレッカンとは、アイラ島付近に発生する渦潮の名前です。
そこからも、力強そうなのがうかがえますね。
テイスティング
色
10年は薄い。コリーブレッカン(今後、コリと呼ぶ)は濃い。琥珀色。
香り
10年は、甘さ、次に柑橘。その中に煙たさもある感じ。いわれてるみたいに、煙で臭い!よりも先に柑橘のいい香りが来る。
コリは、スパイシーさ、オイリーな海。嗅いだ直後は無臭なんだけど、そこからスパイシーさが来る。
これ、コリの方は5年のウィービースティにちょっと似てる気がする。
ストレート
10年は、とにかく口当たりよし。柑橘がきて、最後後味は煙。浅瀬な感じ。
コリは、スパイシーさ。アルコール度数高いだけあって、アルコール感あり。ずっしりくる。大陸棚って感じ。
ちょい加水
10年は、ちょっと薄め?後味がストレートと比べてライトになってる。
コリは、ちょっと飲みやすくなってるが、下のピリつきはある。
トゥワイスアップ
10年は、さわやか8割、スモーキー2割。後味は特にないけど、ぐびぐび飲めそう、おいしい。
コリは、これトゥワイス?ってくらい濃い。すごい。スパイシーさが分かりやすい。これ、コリの味をそのままわかりやすく伝えてる気がする。
ロック
10年は、落ち着いてる。しっとりしてる感じ。後味は、スモーキーと柑橘が5:5で続く。
コリは、舌ピリつく。味が濃い!重厚感ある。ただ、飲みやすいよ。
ハイボール
10年は、弾ける柑橘。スモーキーはほぼない。うますぎ。
コリは、オイリーな煙さ。しっかり味が分かる。
![アードベッグ コリーヴレッカン 箱入 [ ウイスキー イギリス 700ml ]](https://m.media-amazon.com/images/I/41ypXngVnLL._SL500_.jpg "アードベッグ コリーヴレッカン 箱入 [ ウイスキー イギリス 700ml ]")
AWS Certified Solutions Architect – Associate に合格しました
皆さんこんばんは。もうすぐ2022年も1か月が終わりますが、いかがお過ごしでしょうか。
年始に建てた目標との乖離がそろそろ出てきた頃でしょうか。私も、最近ジム通いのペースが落ちてきているので頑張らないと。
と、いうことで、年末から勉強していたAWS Certified Solutions Architect – Associate(AWS SAA)の試験を受けてきました。
結果、803/1000で合格!となりましたので、忘れないうちにブログを更新します。
AWS SAAとは?

AWS Certified Solutions Architect – Associate 認定
AWSの資格内で、真ん中の層であるアソシエイトレベルで、かつアーキテクトとしての知識が求められる資格です。
AWSのサービスを使って、可用性/コスト効率/耐障害性が高いスケーラブルなアーキテクチャを作れるような知識が問われます。
選択問題のみ(複数選べ、もある)で、65問の問題が出ます。72%が合格ラインとなっています。
色々なブログやtwitterや周りの人の声を聴くと、まずはこのAWS SAAを取るのが王道っぽいので、これから取ってみました。
資格取ってよかったこと
広くAWS知ることができるので、業務にも影響あるメリットが多いです。
個人的に、AWSのシステム触るならまず必須で取っておくべきだと思います。
- インフラ部分のエラーなどに強くなる
私のチームでは、アプリ担当とインフラ担当が分かれています。
IAM権限の修正/付与、ネットワークの構築、バックアップや通知の設定などはインフラ担当がやってます。
このあたりでエラー起きたとき、毎回インフラ担当者に見てもらっているのですが、結構な頻度で起きているので担当者が多忙に…。
この試験では上記の基本がわかるようになるので、なんとなくエラーの原因と対応策が分かるようになります。
そのため、インフラ担当者の負担が少し減る!…かも。
- 新しくシステム構築する際に、AWSサービス王道組み合わせが分かる
こういう時はこういう組み合わせ、というのがたくさん出てくるので、なんとなくパターンが頭に入ります。
例えば、踏み台EC2→WEBサーバのEC2をサブネット分けて構築するとか、静的ホスティングならCroudFront+S3でいいよねとか。
後はサービスの組み合わせではないですが、特にDB系のサービスの可用性の担保の仕方が大体わかります。
そのため、「とりあえずこういうことがしたくて、それなりに安全に作っときたい」というときに、アーキテクチャを決められるようになると思います。
書いていて思いましたが、これがまさにソリューションアーキテクトですね。
- 今使っているサービスの知らない機能を知ることができる
とりあえず動かしているだけのサービスだと、意外と知らない機能があったりします。
今のシステムを改めて確認して、改善できそうです。
(例)
・S3のライフサイクル管理
期間を設定しておくと、その期間経過したら削除orS3 Glacierにアーカイブしてくれる。
・DynamoDBのTTL
上と似ているが、有効期限決めておくと経過後に登録しているデータを削除してくれる。
DynamoDBは全件を検索するのがキーをうまく設定しておかないと難しいから、件数増えすぎると大変。
・EC2 Image Builder
EC2のテンプレートみたいなものを作れる。かつ、そこに最初からインストールしておくもののバージョンアップも自動で設定+テストできる。
勉強方法
SAAに関しては勉強方法のブログがめちゃくちゃありますが、一応私も載せておきます。
大体2か月くらいの勉強でした。平日たまに、休日そこそこ。大体50時間くらいかけたかな?
前提
約2年間、AWS上でデータ分析系の業務してます。
ただ、いわゆる普通のシステム構築はしてません。
以下、触ってる/触ってないサービスです。
触ってる:S3、Glue、StepFunctions、SQS、Lambda、SageMaker、DynamoDB、CloudFormation
触ってない:EC2、ELB、Route53、VPC、CloudFront、RDS、Aurora
前半1か月の過ごし方
とりあえず、この資格で出てくるサービスを広く浅く理解しよう!と思い、勉強しました。
具体的に使ったのは、以下の2つです。どちらもかなり良かった。
①書籍:AWS認定資格試験テキスト AWS認定ソリューションアーキテクト - アソシエイト 改訂第2版
広く浅く、SAAで出てくるサービスを紹介してくれています。
さらっと目を通すのを何周かするのがおすすめ。
確かにこの本に載っていない機能についての問題が出ることもありますが、そこまで多くない印象でした。

②Udemy講座:【2022年版】これだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座
この講座は、控えめに言ってGODです。
ボリュームすごい(全部で40時間以上)、1つ1つが分かりやすい、ハンズオンついてる、模擬試験3つついてる
この内容で、2000円くらい。(udemyのセールの時に買うともっと安い!)
これは全人類見るべきだと思います。
といっても、さすがにこれ全部やるのは大変なので、以下だけやりました。
これらは、この試験でもよく出てくるところなので、ハンズオンもしっかりやることをお勧めします。
ハンズオンでやってやった操作内容がテストに出ることはあまりないですが、知識の定着が早まった気がします。
・全体像【Selction1~3】
・IAM【Selction4】
・VPC【Selction5】
・EC2【Selction6】
・信頼性の設計(ELB/Auto Scaling/RDS)【Selction9】
後半1か月の過ごし方
大体全体的に知識がついたので、過去問を解く&分からなかったところを調べるを繰り返しました。
具体的には、前半で紹介した②のUdemyの最後についてきた模試と、この講座。
③【2022年版】AWS 認定ソリューションアーキテクト アソシエイト模擬試験問題集(6回分390問)
この模擬試験を3回分受けました。(6回受けたかったけど、時間がなく断念…)
本番よりも難しいと書いてありましたが、確かにそう感じました。この模試だと60%くらいしか取れませんでしたが、本番は80%取れたので。
ただ、この模試の難しさは、どちらかというと「試験では聞いてこないような機能についても聞かれる」難しさな感じがします。
本番は、模試よりも問題文が長く、直接すぐ答えられるような問題が少ないです(取り出しに5時間時間かかってよい時は?→S3 Glacier標準 など)。
なので、この模試もそうですが、問題文と答えを暗記するというよりは、「こういう条件だから、このサービスのこの機能を使ってるのか」と理解するのが大事だと思います。
www.udemy.com

書籍「実践的データ基盤への処方箋」を読んだ
今年初めての5連続仕事を乗り切った皆様、お疲れさまでした。いかがお過ごしでしょうか。
今日は、私の業務にも関係している、データ基盤に関しての本を読んだので自分的なまとめを書いていこうと思います。
どんな本?

一言でいうと、「データ基盤作りました!だけじゃダメなんよ」という本。
冒頭で、著者はこのように言っている。
- 真のデータ活用とは、一時的ではなく、継続的に企業の成長を支えることである。
- しかし、企業においてこれができているかというと、そうではない。
- データ基盤の作り方のノウハウは世間的にも認知されてきているのに、なぜか?
- 「データ基盤の活用のさせ方」が広まっていないからである。
確かに、データ基盤の作り方という意味では、巷にはパブリッククラウドを使ったハンズオンや、pythonの書籍などがあふれかえっている。
それにも関わらず、データ分析基盤作りがうまくいかない!という声は、よく聞くように思える。
思うと、こういうギャップは日常生活でもよく起きているように思う。
- 実家の親がスマホに変えたいということで手続して変えてあげたが、使いにくそうにしている。
- 仕事でチームのタスク管理のためにチケット管理ツールを導入したが、だれも使ってない。
- 同居人が「初めて資料作成の仕事を任された」というので、実際に自分が参考にした書籍やサイトを送ったが、何も見ない。
このように、使う側と提供する側が違うと、このようなことが起こりうるのだろう。
今回は、その「データ分析基盤版」というわけだ。(キバンバンって語呂悪いな…)
この本では、実際のビジネスの現場で起きた課題、解決したノウハウをデータ/システム/ヒトの観点で紹介している。
今回は、その中でも私が重要だと思った「データ」の観点の中から、特に大事なべし/べからずをピックアップして紹介する。
ユースケースからつくるべし(not データ基盤)【1-9】
why?
ユースケースがビジネス価値を生むものだから。基盤だけ整えても、「結局何がしたかったんだっけ?」となりがち。
how?
- 自社の目標、現状、課題、施策を洗い出す。
- 施策の優先順位を決める。
- その施策の中で、「どの顧客or社員の」「どの作業or判断を」「どのように置き換えるか」を検討する。
(例)
デジタル広告配信による登録促進、という施策の場合。
・経営企画部門が売り上げを集計している→手間削減のためにダッシュボードを作る
・顧客自らページをクリックして商品を探している→手間削減のために検索機能を作る
このあたりのユースケースへの落とし込みは、この本だけだと詳細には分からなかった。
著者からも、「業務改善やUXデザインの手法が役に立つからほかの書籍を参考にしてみてね」ということだった。
この部分に関しては、このブログ記事がよく言語化されている。
ただ、やはり実際の経験が積みたいところ。仕事であればいいが、なにか過去事例などないものか…。
【保存版】初心者でも分かるデータ分析の本質とスキルアップの道のり|naki|note
サービスレベルを設定/計測して継続的に改善するべし【1-11】
why?
ユーザが期待しているサービスレベルをクリアしないと使われなくなっていくから。
how?
ユースケースごとにサービスレベルを設定し、そのサービスレベルが守れているかを定期的にモニタリングする。
(例)
毎営業日の午前9時までに欠損なく前日の売り上げレポートが作成されていること
この「サービスレベル」は、なかなか難しい。なぜなら、ユーザにざっくり「守るべきサービスレベルって何にすればいいですか?」と聞いても答えが返ってこないだろうからだ。
(もちろん、例のようにはっきりしているものもあるだろうが、ユーザの暗黙的な期待もあるはず。)
SIer思考だと、サービスレベルの種類を網羅したどでかいexcelがどこかにあって、その1行ごとにレベルを定義してユーザと合意したくなる。
以下の非機能グレードのように。
システム構築の上流工程強化(非機能要求グレード):IPA 独立行政法人 情報処理推進機構
ただ、データ分析基盤では、とりあえずエイヤで分かりやすいレベルだけ決めて、定期的に振り返っていき、途中で何か問題が起きたらサービスレベルに追加していくのがいいのだろう。
例えば、nullが入らないはずのidカラムにnullが入ってしまっている、という障害が起きたら、csvファイルのnullチェックを実装してモニタリングする、など。
著者の1人であるゆずたそさんのブログで、この部分はより詳細に述べられていた。
サービスレベル:設計と運用のプラクティス - 下町柚子黄昏記 by @yuzutas0
また、オライリーのこの書籍も参考になりそうだ。

利害対立が生じる、データの生成者と活用者をうまくつなげるべし【1-3, 1-10】
why?
- データが高品質で利用できる形で生成されないと、データ活用者がデータをうまく使えないから。
- データソースに一番詳しいデータ生成者がメタデータの更新作業をしてもらわないと、データ活用者のデータ調査コストが膨れ上がるため。
おわりに
以上、重要そうなところだけをピックアップし、参考になりそうなものがあれば載せてみた。
この中でも特に重要なのは、1つ目のユースケースに関わるところだろう。
ユースケースがうまく決まれば、あとはそれをどう検証/実現していくかという話になるので、動きが速い。
また、ユースケースはビジネス価値に直結するので周りも説得させやすい。
インフラエンジニアでも、データスチュワードでも、「どのようにビジネス価値につながっているのか」は、常に意識しておくべきだろう。
案件が来るたびに、それを確認するような仕組みを作っておくとよいかもしれない。
仕組みは文化を創り出す。ビジネス価値を意識できるチームは、強いチームになれるはずだ。
アードベッグ5年と10年飲み比べ
変わらず寒い日が続く昨今、皆様お元気でしょうか。
そんな寒い日は、やはりお酒を飲んで暖かくなりたくなりますね。
それも、暖炉の前で、ウイスキーのストレートをぐびっとやりたくなるものです。
ということで、今日は私の大好きなウイスキー、アードベッグ10年と5年の飲み比べ記事です。
そもそもアードベッグとは何か。
・ピート臭(焦げ臭い、薬品臭い)がすごいことで有名。
・今回のむTENがスタンダード品。
・これを好きな人々はアードベギャンと呼ばれる
という知る人ぞ知る名ウイスキーです。
年に1度、アードベッグデイというイベントが行われ、そこで毎年新作が飲めます。(その新作をボトルで買うのはかなり大変。このイベントで飲むことはできる)
さて、上記の通りTENはスタンダード品ですが、2020年に発売したのがこのアードベッグ5年 WEE BEASTIEです。
あまりそこら辺でも売っていないというのをネットで見ましたが、近くのカクヤスで売っていたので購入。
そして、年末になくなっていたアードベッグTENを購入したので、この記事を書くことにしました。

ご尊顔。
まず、ボトルがかっこいいですよね。ミドリのボトルに黒メインの色遣いが厨二心をくすぐります。
5年の方の赤もワンポイントでかっこいい。最高。
テイスティング
色
5年の方がちょっと濃いめ。10年は薄い。
5年の方は、少し赤見がかかってる?
香り
5年は、炭+オイリーな感じ。なんか重い、のっぺりした感じ。このオイリーさ、私はちょっと苦手。
10年は、潮っけ。からのちょい甘さ、柑橘。嗅ぐと海が頭に広がる。
ストレート
5年は、香りの方にあったオイリーさが来る。フィニッシュにかけては炭っぽさ、苦み。香りがそのまま味に反映されている。
10年は、やはり潮っぽさ。口いっぱいに広がる。後味は爽やか系。しょっぱさの中に炭な感じ。
ちょい加水
5年は、ストレートとかにあったオイリーさが薄まってちょっと飲みやすく感じた。
このオイリーさ、なんだろうと思ったけど、この前かったロイヤルロッホナガー12年にちょっと似ている。
シェリー樽の味なのかな?(この5年はオロロソシェリー樽を使っているらしい)
10年は、ちょい加水すると後味に合った炭ぽさが強くなってきた。
トゥワイスアップ
5年は、ちょっとしょっぱい感じになってきた。後味のところは薄まって、ほぼない。
10年は、柑橘感がかなり出てくる。炭っぽさはほぼなくなる。
しかし、トゥワイスにしても両者しっかりウイスキーの味がする。さすが。
ロック
5年は、ロックにするとごくごく飲める。上にあったオイリーさはあるけど、奥の方に炭がいる。
10年は、しょっぱさ、そして青りんご感。炭感はあんまりない。
ハイボール
5年は、やはり一貫してオイリー感。ただ、それがシュワっとなった感じ。うまいけど、なんかちょっと重い。
10年は、柑橘感がメインでサブに炭っぽい燻製感。爽快感すごい。ってかマジでうまい。
![アードベッグ 10年 箱入り [ ウイスキー イギリス 700ml ]](https://m.media-amazon.com/images/I/41JPgWftNrL._SL500_.jpg "アードベッグ 10年 箱入り [ ウイスキー イギリス 700ml ]")
データ分析系ツール総まとめ
皆さんあけましておめでとうございます。今年もどうぞよろしくお願いします。
前置き
最近、データ分析系のツールが巷に乱立していますね。
あっちではAutoML搭載のツールが出た、こっちではOSSでデータ品質をチェックできるツールが出た、と毎日のようにアップデートされていきます。
最新情報もいいですが、一旦ここらで腰を据えて、大御所ツール群を体系的に知っておくことは、必要だと思います。
ということで、今回は、データ分析系のツールを(主に)DMBOK観点で、(大体)ガートナーのマジッククアドラント(以下、MQと呼ぶ)を使ってまとめていきたいと思います。
・DMBOKとは?
データマネジメント知識体系(Data Management Body Of Knowledge)の略です。SIerの方には、「PMBOKのデータ管理バージョン」といった方が分かりやすいでしょうか。
米国のDAMAという団体が、「データを管理するとき、こんなことすればうまくいくでー!」というノウハウを1つにまとめたのがこれです。
本はでかくて分厚い、かつ内容が難しいという初心者泣かせの書籍です。
・ガートナーのMQとは?
ガートナー社が年に1度出している、「各領域で強いやつらを決めようゼ!大会」の結果です。
「gartner magic quadrant」とググるとイメージつくと思います。
その領域のサービスを提供している会社を、第4象限に分類しているグラフがそれです。
まとめ方
まとめる軸について
上で記載した通り、基本はDMBOKの11領域ごとに調査します。
ただ、以下の4領域は除外しています。
「データアーキテクチャ」「データカバナンス」:ツールを使ってどうこうという領域ではないため。
「データストレージ」「データセキュリティ」:ガートナーのMQになかったため。
また、DMBOKになかった「機械学習」という領域を追加しています。昨今のデータ分析には必須であるためです。
さらに、細かいですが「DWHとBI」という領域は、「DWH」「BI」と2つに分けました。それぞれツールが全然違うからです。
軸ごとのツールの選び方
基本的には、MQの
リーダー(第1象限)
チャレンジャー(第2象限)
概念先行型(第4象限)
の3つに記載されているツールを抽出します。特定市場指向型(第3象限)はまだ有名どころじゃないので除外してます。
それぞれのMQのリンクは最後に載せますが、本物のMQは見るのにお金がかかります。
そのため、各ツールベンダーが「俺のツールがMQに乗ったぜ!いぇーい!」と言わんばかりに見せつけているページを調査対象としています。
また、データモデリングはMQが見つからなかったので、適当にググったまとめサイトから持ってきています。Top10まであったのでTop5までをLeader扱いで載せてます。
そして、ドキュメントも見つからなかったので「Enterprise Agile Planning Tools」というMQから持ってきています。wiki系のツールがたくさん載っていたからです。
結果
結果の見方
MQの象限ごとに、セルの色を塗りつぶしています。
リーダー(第1象限):緑
チャレンジャー(第2象限):青
概念先行型(第4象限):赤
また、まとめていたら以下のように分けた方が分かりやすかったので、結果の表は2つできています。
①複数領域の機能を有するツール群
②単独領域機能しか持たないツール群
一応注意ですが、これはMQから抽出した結果です。
「xxのツールはこの機能も持ってるよ!!」という指摘はめちゃくちゃあると思います。というか私がありました。
文句はガートナーに言ってください。


終わりに
こういうまとめ方しておいてなんですが、
IBM、SAP最強!!!これだけ知ってればベンダー的にもオールオッケー!!
とはいかないのが難しいところ。
特に、AWS/GCP/Azureを使っているたくさんの人々は、いったい何を使えば幸せなのか?は余計にわからなくなった気がします。
ただ、今後はこの3つの動きが出ていくのではないかな、と思います。
・クラウドベンダが足りない領域を自分で作る or どこかの会社を買収する
・IBMやSAPなどの強強ベンダーが足りない機能を補強していく
・圧倒的な差別化要素(特許出してる技術など)で突き抜けた一転集中型サービスが出てくる
私個人としては、クラウドベンダが足りないところを作ってくれた方が楽だなぁと思います。ただ、ツールベンダはそれだと嬉しくないわけで、どのように展開していくかは見ものですね。
あまりまとまりのない記事になってしまいましたが、以上!
参考文献
上でも記載していますが、MQの本文ではなく、各ベンダがニュースで載せているリンクです。
2022年1月5日現在は見れていますが、今後見れなくなる可能性は十分ありますのでご注意ください。
- データクオリティ
ガートナー社の2021年データ品質ソリューションのマジック・クアドラント | Informatica Japan
2020年のしか見つからなかった。
ガートナー社の2020年メタデータ管理ソリューションのマジック・クアドラント | Informatica Japan
- DWH
2020年のしか見つからなかった。
Teradata Leads in Gartner Magic Quadrant for Cloud Database
- BI
2021年 ガートナー アナリティクス& BIプラットフォームについてのマジック・クアドラント
- マスタデータ
2021 Gartner Magic Quadrant for Master Data Management Solutions | TIBCO Software
- ドキュメント、コンテンツ管理
Enterprise Agile Planning Toolsというちょっと違う領域から持ってきている。ツール群が大体この領域だと判断したため。
Atlassian - a Leader in Gartner's Magic Quadrant
- データ統合
クラウドアナリティクスおよびクラウドデータ管理のための業界最高のクラウドネイティブデータ統合 | Informatica Japan
- データモデリング
ガートナーじゃない、ググって出てきたサイト。
Top 10 Data Modeling Tools to Know in 2021 - Spectral
MathWorks、ガートナー社の 2021 年のマジック・クアドラントでリーダーの 1 社と評価 - MATLAB & Simulink